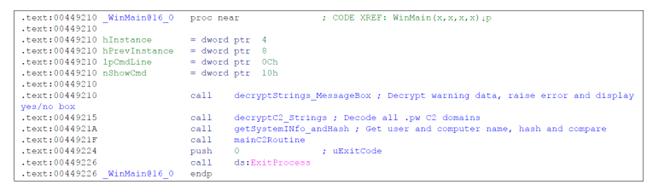
Today, CISA, the National Security Agency, the Federal Bureau of Investigation, and international partners released a joint Cybersecurity Information Sheet on AI Data Security: Best Practices for Securing Data Used to Train & Operate AI Systems.
This information sheet highlights the critical role of data security in ensuring the accuracy, integrity, and trustworthiness of AI outcomes. It outlines key risks that may arise from data security and integrity issues across all phases of the AI lifecycle, from development and testing to deployment and operation.
Defense Industrial Bases, National Security Systems owners, federal agencies, and Critical Infrastructure owners and operators are encouraged to review this information sheet and implement the recommended best practices and mitigation strategies to protect sensitive, proprietary, and mission critical data in AI-enabled and machine learning systems. These include adopting robust data protection measures; proactively managing risks; and strengthening monitoring, threat detection, and network defense capabilities.
As AI systems become more integrated into essential operations, organizations must remain vigilant and take deliberate steps to secure the data that powers them. For more information on securing AI data, see CISA’s Artificial Intelligence webpage.
This information sheet highlights the critical role of data security in ensuring the accuracy, integrity, and trustworthiness of AI outcomes. It outlines key risks that may arise from data security and integrity issues across all phases of the AI lifecycle, from development and testing to deployment and operation.
Defense Industrial Bases, National Security Systems owners, federal agencies, and Critical Infrastructure owners and operators are encouraged to review this information sheet and implement the recommended best practices and mitigation strategies to protect sensitive, proprietary, and mission critical data in AI-enabled and machine learning systems. These include adopting robust data protection measures; proactively managing risks; and strengthening monitoring, threat detection, and network defense capabilities.
As AI systems become more integrated into essential operations, organizations must remain vigilant and take deliberate steps to secure the data that powers them. For more information on securing AI data, see CISA’s Artificial Intelligence webpage.
Executive summary
This Cybersecurity Information Sheet (CSI) provides essential guidance on securing data used in artificial intelligence (AI) and machine learning (ML) systems. It also highlights the importance of data security in ensuring the accuracy and integrity of AI outcomes and outlines potential risks arising from data integrity issues in various stages of AI development and deployment.
This CSI provides a brief overview of the AI system lifecycle and general best practices to secure data used during the development, testing, and operation of AI-based systems. These best practices include the incorporation of techniques such as data encryption, digital signatures, data provenance tracking, secure storage, and trust infrastructure. This CSI also provides an in-depth examination of three significant areas of data security risks in AI systems: data supply chain, maliciously modified (“poisoned”) data, and data drift. Each section provides a detailed description of the risks and the corresponding best practices to mitigate those risks.
This guidance is intended primarily for organizations using AI systems in their operations, with a focus on protecting sensitive, proprietary, or mission critical data. The principles outlined in this information sheet provide a robust foundation for securing AI data and ensuring the reliability and accuracy of AI-driven outcomes.
This document was authored by the National Security Agency’s Artificial Intelligence Security Center (AISC), the Cybersecurity and Infrastructure Security Agency (CISA), the Federal Bureau of Investigation (FBI), the Australian Signals Directorate’s Australian Cyber Security Centre (ASD’s ACSC), the New Zealand’s Government Communications Security Bureau’s National Cyber Security Centre (NCSC-NZ), and the United Kingdom’s National Cyber Security Centre (NCSC-UK).
The goals of this guidance are to:
Raise awareness of the potential risks related to data security in the development, testing, and deployment of AI systems;
Provide guidance and best practices for securing AI data across various stages of the AI lifecycle, with an in-depth description of the three aforementioned significant areas of data security risks; and
Establish a strong foundation for data security in AI systems by promoting the adoption of robust data security measures and encouraging proactive risk mitigation strategies.
Download the PDF version of this report:
AI Data Security (PDF, 799 KB).
Introduction
The data resources used during the development, testing, and operation of an AI1 system are a critical component of the AI supply chain; therefore, the data resources must be protected and secured. In its Data Management Lexicon, [1] the Intelligence Community (IC) defines Data Security as “The ability to protect data resources from unauthorized discovery, access, use, modification, and/or destruction…. Data Security is a component of Data Protection.”
Data security is paramount in the development and deployment of AI systems. Therefore, it is a key component of strategies developed to safeguard and manage the overall security of AI-based systems. Successful data management strategies must ensure that the data has not been tampered with at any point throughout the entire AI system lifecycle; is free from malicious, unwanted, and unauthorized content; and does not have unintentional duplicative or anomalous information. Note that AI data security depends on robust, fundamental cybersecurity protection for all datasets used in designing, developing, deploying, operating, and maintaining AI systems and the ML models that enable them.
Audience and scope
This CSI outlines potential risks in AI systems stemming from data security issues that arise during different phases of an AI deployment, and it introduces recommended protocols to mitigate these risks. This guidance builds upon the NSA’s joint guidance on Deploying AI Systems Securely [2] and delves deeper into securing the data used to train and operate AI-based systems. This guidance is primarily developed for organizations that use AI systems in their day-to-day operations, including the Defense Industrial Base (DIB), National Security System (NSS) owners, Federal Civilian Executive Branch (FCEB) agencies, and critical infrastructure owners and operators. Implementing these mitigations can help secure AI-enabled systems and protect proprietary, sensitive, and/or mission critical data.
Securing data throughout the AI system lifecycle
Data security is a critical enabler that spans all phases of the AI system lifecycle. ML models learn their decision logic from data, so an attacker who can manipulate the data can also manipulate the logic of an AI-based system. In the AI Risk Management Framework (RMF) [3], the National Institute of Standards and Technology (NIST) defines six major stages in the lifecycle of AI systems, starting from Plan & Design and progressing all the way to Operate & Monitor. The following table highlights relevant data security factors for each stage of the AI lifecycle:
Table 1: The AI System Lifecycle with key dimensions, necessary ongoing assessments, focus areas for data security, and particular data security risks covered in this CSI. [3]
AI Lifecycle Stage
Key Dimensions
Test, Evaluation, Verification, & Validation (TEVV)
Potential Focus Areas for Data Security
Particular Data Security Risks Covered in this CSI
1) Plan & Design
Application Context
Audit & Impact Assessment
Incorporating data security measures from inception, designing robust security protocols, threat modeling, and including privacy by design
Data supply chain
2) Collect & Process Data
Data & Input
Internal & External Validation
Ensuring data integrity, authenticity, encryption, access controls, data minimization, anonymization, and secure data transfer
Data supply chain,maliciously modified data
3) Build & Use Model
AI Model
Model Testing
Protecting data from tampering, ensuring data quality and privacy (including differential privacy and secure multi-party computation when appropriate and possible), securing model training, and operating environments
Data supply chain,maliciously modified data
4) Verify & Validate
AI Model
Model Testing
Performing comprehensive security testing, identifying and mitigating risks, validating data integrity, adversarial testing, and formal verification when appropriate and possible
Data supply chain,maliciously modified data
5) Deploy & Use
Task & Output
Integration, Compliance Testing, Validation
Implementing strict access controls, zero-trust infrastructure, secure data transmission and storage, secure API endpoints, and monitoring for anomalous behavior
Data supply chain,maliciously modified data,data drift
6) Operate & Monitor
Application Context
Audit & Impact Assessment
Conducting continuous risk assessments, monitoring for data breaches, deleting data securely, complying with regulations, incident response planning, and regular security auditing
Data supply chain,maliciously modified data, data drift
Throughout the AI system lifecycle, securing data is paramount to maintaining information integrity and system reliability. Starting with the initial Plan & Design phase, carefully plan data protection measures to provide proactive mitigations of potential risks. In the Collect & Process Data phase, data must be carefully analyzed, labeled, sanitized, and protected from breaches and tampering. Securing data in the Build & Use Model phase helps ensure models are trained on reliably sourced, accurate, and representative information. In the Verify & Validate phase, comprehensive and thorough testing of AI models, derived from training data, can identify security flaws and enable their mitigation.
Note that Verification & Validation is necessary each time new data or user feedback is introduced into the model; therefore, that data also needs to be handled with the same security standards as AI training data. Implementing strict access controls protects data from unauthorized access, especially in the Deploy & Use phase. Lastly, continuous data risk assessments in the Operate & Monitor phase are necessary to adapt to evolving threats. Neglecting these practices can lead to data corruption, compromised models, data leaks, and non-compliance, emphasizing the critical importance of robust data security at every phase.
Best practices to secure data for AI-based systems
The following list contains recommended practical steps that system owners can take to better protect the data used to build and operate their AI-based systems, whether running on premises or in the cloud. For more details on general cybersecurity best practices, see also NIST SP 800-53, “Security and Privacy Controls for Information Systems and Organizations.” [33]
1. Source reliable data and track data provenanceVerify data sources use trusted, reliable, and accurate data for training and operating AI systems. To the extent possible, only use data from authoritative sources. Implement provenance tracking to enable the tracing of data origins, and log the path that data follows through an AI system. [7],[8],[9] Incorporate a secure provenance database that is cryptographically signed and maintains an immutable, append-only ledger of data changes. This facilitates data provenance tracking, helps identify sources of maliciously modified data, and helps ensure that no single entity can undetectably manipulate the data.2. Verify and maintain data integrity during storage and transportMaintaining data integrity2 is an essential component to preserve the accuracy, reliability, and trustworthiness of AI data. [4] Use checksums and cryptographic hashes to verify that data has not been altered or tampered with during storage or transmission. Generating such unique codes for AI datasets enables the detection of unauthorized changes or corruption, safeguarding the information’s authenticity.
3. Employ digital signatures to authenticate trusted data revisionsDigital signatures help ensure data integrity and prevent tampering by third parties. Adopt quantum-resistant digital signature standards [5][6] to authenticate and verify datasets used during AI model training, fine tuning, alignment, reinforcement learning from human feedback (RLHF), and/or other post-training processes that affect model parameters. Original versions of the data should be cryptographically signed, and any subsequent data revisions should be signed by the person who made the change. Organizations are encouraged to use trusted certificate authorities to verify this process.4. Leverage trusted infrastructureUse a trusted computing environment that leverages Zero Trust architecture. [10] Provide secure enclaves for data processing and keep sensitive information protected and unaltered during computations. This approach fosters a secure foundation for data privacy and security in AI data workflows by isolating sensitive operations and mitigating risks of tampering. Trusted computing infrastructure supports the integrity of data processes, reduces risks associated with unverified or altered data, and ultimately creates a more robust and transparent AI ecosystem. Trusted environments are essential for AI applications where data accuracy directly impacts their decision-making processes.5. Classify data and use access controlsCategorize data using a classification system based on sensitivity and required protection measures. [11] This process enables organizations to apply appropriate security controls to different data types. Classifying data enables the enforcement of robust protection measures like stringent encryption and access controls. [33] In general, the output of AI systems should be classified at the same level as the input data (rather than creating a separate set of guardrails).6. Encrypt dataAdopt advanced encryption protocols proportional to the organizational data protection level. This includes securing data at rest, in transit, and during processing. AES-256 encryption is the de facto industry standard and is considered resistant to quantum computing threats. [12],[13] Use protocols, such as TLS with AES-256 or post-quantum encryption, for data in transit. Refer to NIST SP 800-52r2, “Guidelines for the Selection, Configuration, and Use of Transport Layer Security (TLS) Implementations” [14] for more details.7. Store data securelyStore data in certified storage devices that enforce NIST FIPS 140-3 [15] compliance, ensuring that the cryptographic modules used to encrypt the data provide high-level security against advanced intrusion attempts. Note that Security Level 3 (defined in NIST FIPS 140-2 [16]) provides robust data protection; however, evaluate and determine the appropriate level of security based on organizational needs and risk assessments.8. Leverage privacy-preserving techniques There are several privacy-preserving techniques [17] that can be leveraged for increased data security. Note that there may be practical limitations to their implementation due to computational cost.
Data depersonalization techniques (e.g., data masking [18]) involve replacing sensitive data with inauthentic but realistic information that maintains the distributions of values throughout the dataset. This enables AI systems to utilize datasets without exposing sensitive information, reducing the impact of data breaches and supporting secure data sharing and collaboration. When possible, use data masking to facilitate AI model training and development without compromising sensitive information (e.g., personally identifiable information [PII]).
Differential privacy is a framework that provides a mathematical guarantee quantifying the level of privacy of a dataset or query. It requires a pre-specified privacy budget for the level of noise added to the data, but there are tradeoffs between protecting the training data from membership inference techniques and target task accuracy. Refer to [17] for further details.
Decentralized learning techniques (e.g., federated learning [19]) permit AI system training over multiple local datasets with limited sharing of data among local instances. An aggregator model incorporates the results of the distributed models, limiting access on the local instance to the larger training dataset. Secure multi-party computation is recommended for training and inferencing processes.
9. Delete data securelyPrior to repurposing or decommissioning any functional drives used for AI data storage and processing, erase them using a secure deletion method such as cryptographic erase, block erase, or data overwrite. Refer to NIST SP 800-88, “Guidelines for Media Sanitization,” [20] for guidance on appropriate deletion methods.10. Conduct ongoing data security risk assessmentsConduct ongoing risk assessments using industry-standard frameworks, such as the NIST SP 800-3r2, Risk Management Framework (RMF) [4][21], and the NIST AI 100-1, Artificial Intelligence RMF [3]. These assessments should evaluate the AI data security landscape, identify risks, and prioritize actions to minimize security incidents. Continuously improve data security measures to keep pace with evolving threats and vulnerabilities, learn from security incidents, stay up to date with emerging technologies, and maintain a robust security posture.
Data supply chain – risks and mitigations
Relevant AI Lifecycle stages: 1) Plan & Design; 2) Collect & Process Data; 3) Build & Use Model; 4) Verify & Validate; 5) Deploy & Use; 6) Operate & Monitor
Developing and deploying secure and reliable AI systems requires understanding potential risks and methods of introducing inaccurate or maliciously modified (a.k.a. “poisoned”) data into the system. In short, the security of AI systems depends on thorough verification of training data and proactive measures to detect and prevent the introduction of inaccurate material.
Threats can stem from large-scale data collected and curated by third parties, as well as from data that is not sufficiently protected after ingestion. Data collected and/or curated by a third party may contain inaccurate information, either unintentionally or through malicious intent. Inaccurate material can compromise not only models trained using that data, but also any additional models that rely on compromised models as a foundation.
It is crucial, therefore, to verify the integrity of the training data used when building an AI system. Organizations that utilize third-party data must take appropriate measures to ensure that: 1) the data is not compromised upon ingestion; and 2) the data cannot be compromised after it has been incorporated into the AI system. As such, both data curators and data consumers should follow the best practices for digital signatures, data integrity, and data provenance that are described in detail above.
General risks for data consumers3
The use of web-scale databases includes all of the risks outlined earlier, and one cannot simply assume that these datasets are clean, accurate, and free of malicious content. Third-party models trained on web-scraped data used to train a model for downstream tasks could also affect the model’s learning process and result in behavior that was unintended by the AI system designer.
From the moment data is ingested for use with AI systems, the data acquirer must secure it against insider threats and malicious network activity to prevent unauthorized modification.
Mitigation strategies:
Dataset verification: Before ingest, the consumer or curator should verify, as much as possible, that the dataset to be ingested is free of malicious or inaccurate material. Any detected abnormalities should be addressed, and suspicious data should not be stored. The dataset verification process should include a digital signature of the dataset at time of ingestion.
Content credentials: Use content credentials to track the provenance of media and other data. Content credentials are “metadata that are secured cryptographically and allow creators the ability to add information about themselves or their creative process, or both, directly to media content…. Content Credentials securely bind essential metadata to a media file that can track its origin(s), any edits made, and/or what was used to create or modify the content…. This metadata alone does not allow a consumer to determine whether a piece of content is ‘true,’ but rather provides contextual information that assists in determining the authenticity of the content.” [24]
Foundation model assurances: In the case where a consumer is not ingesting a dataset but a foundation model trained by another party, the developers of the foundation model need to be able to provide assurances regarding the data and sources used and certify that their training data did not contain any known compromised data. Take care to track the training data used in various model lineages. Exercise caution before using a model without such assurances.
Require certification: Data consumers should strongly consider requiring a formal certification from dataset and model providers, attesting that their systems are free from known compromised data before using third-party data and/or foundation models.
Secure storage: After ingest, data needs to be stored in a database that adheres to the best practices for digital signatures, data integrity, and data provenance that are described in detail above. Note that an append-only cryptographically signed database should be used where feasible, but there may be a need to delete older material that is no longer relevant. Each time a data element is updated (e.g., resized, cropped, flipped, etc.) for augmentation purposes in a non-temporary fashion, then the updated data should be stored as a new entry with documented changes. The database’s certificate should be verified at the time the database is accessed for a training run. If the database does not pass the certificate check, abort the training and conduct a comprehensive database audit to discover any data modifications.
2023 investigations by various industry professionals explored low-resource methods for introducing malicious or inaccurate material into web-scale datasets, and potential strategies to mitigate this risk. [29] These vulnerabilities depend on the fact that curators or collectors do not have control over the data, as seen in cases of datasets curated by third parties (e.g., LAION) or datasets that are continually updated and released (e.g., Wikipedia).
Risk: Curated web-scale datasets
Curated AI datasets (e.g., LAION-2B or COYO-700M) are vulnerable to a type of technique known as split-view poisoning. This risk arises because these datasets often contain data hosted on domains that may have expired or are no longer actively maintained by their original owners. In such cases, anyone who purchases these expired domains gains control over the content hosted on them. This situation creates an opportunity for malicious actors to modify or replace the data that the curated list points to, potentially introducing inaccurate or misleading information into the dataset. In many instances, it is possible to purchase enough control of a dataset to conduct effective poisoning for roughly $1,000 USD. In some cases, effective techniques can cost as little as $60 USD (e.g., COYO-700M), making this a viable threat from low-resource threat actors.
Mitigation strategies:
Raw data hashes: Data curators should attach a cryptographic hash to all raw data referenced in the dataset. This will enable follow-on data consumers to verify that the data has not changed since it was added to the list.
Hash verification: Data consumers should incorporate a hash check at time of download in order to detect any changes made to it, and the downloader should discard any data that does not pass the hash check.
Periodic checks: Curators should periodically scrape the data themselves to verify that the data has not been modified. If any changes are detected, the curator should take appropriate steps to ensure the data’s integrity.
Verifying data: Curators should verify that any changed data is clean and free from inaccurate or malicious material. If the content of the data has been altered in any way, the curator should either remove it from their list or flag it for further review.
Certification by curators: Since the data supply chain begins with the curators, the certification process must start there as well. To the best of their ability, curators should be able to certify that, at the time of publication, the dataset contains no malicious or inaccurate material.
Risk: Collected web-scale datasets
Collected web-scale datasets (e.g., Wikipedia) are vulnerable to frontrunning poisoning techniques. Frontrunning poisoning occurs when an actor injects malicious examples in a short time window before websites with crowd-sourced content collect a snapshot of their data. Wikipedia in particular conducts twice-monthly snapshots of their data and publishes these snapshots for people to download. Since the snapshots happen at known times, it is possible for malicious actors to edit pages close enough to the snapshot time so that malicious edits will be captured and published before they can be discovered and corrected. Industry analysis demonstrated potential malicious actors would be able to successfully poison as much as 6.5% of Wikipedia. [29]
Mitigation strategies:
Test & verify web-scale datasets: Be cautious when using web-scale datasets that are vulnerable to frontrunning poisoning. Check that the data hasn’t been manipulated, and only use snapshots verified by a trusted party.
(For web-scale data collectors) Randomize or lengthen snapshots: Collectors such as Wikipedia should defend against actors making malicious edits ahead of a planned snapshot by:
Randomizing the snapshot order.
Freezing edits to content long enough for edits to go through review before releasing the snapshot.
These mitigations focus on increasing the amount of time a malicious actor must maintain control of the data for it to be included in the published snapshot. Any reasonable methods that increase the time a malicious actor must control the data are also recommended.
Note that these mitigations are limited since they rely on trusted curators who can detect malicious edits. It is more difficult to defend against subtle edits (e.g., attempts to insert hidden watermarks) that appear valid to human reviewers but impact machine understanding.
Risk: Web-crawled datasets
Web-crawled datasets present a unique intersection of the risks discussed above. Since web-crawled datasets are substantially less curated than other web-scale datasets, they bring increased risk. There are no trusted curators to detect malicious edits. There are no original curated views to which cryptographic hashes can be attached. The unfortunate reality is that “updates to a web page have no realistic bound on the delta between versions which might act as a signal for attaching trust.” [29]
Mitigation strategies:
Consensus approaches: Data consumers using web-crawled datasets should rely on consensus-based approaches, since notional determinations of which domains to trust are ad-hoc and insufficient. For example, an AI developer could choose to only trust an image-caption pair when it appears on many different websites to reduce susceptibility to poisoning techniques, since a malicious actor would have to poison a sufficiently large number of websites to be successful.
Data curation: Ultimately, it is incumbent on organizations to ensure malicious or inaccurate material is not present in the data they use. If an organization does not have resources to conduct the necessary due diligence, then the use of web-crawled datasets is not recommended until some sort of trust infrastructure can be implemented.
Final note on web-scale datasets and data poisoning
Both split-view and frontrunning poisoning are reasonably straightforward for a malicious actor to execute, since they do not require particularly sophisticated methodology. These poisoning techniques should be considered viable threats by anyone looking to incorporate web-scale data into their AI systems. The danger here comes not only from directly using compromised data, but also from using models which may themselves have been trained on compromised data.
Ultimately, data poisoning must be addressed from a supply chain perspective by those who train and fine-tune AI models. Proper supply chain integrity and security management (i.e., selecting reliable model providers and verifying the legitimacy of the models used) can reduce the risk of data poisoning and system compromise. The most reliable providers are those who assure that they do everything possible to prevent the influence and distribution of poisoned data and models. [34]
Every effort must be made by those building foundation models to filter out malicious and inaccurate data. Foundation models are evolving rapidly, and filtering out inaccurate, unauthorized, and malicious training data is an active area of research, particularly at web-scale. As such, is currently impractical to prescribe precise methods for doing so; it is a best-effort endeavor. Ideally, data curators and foundation model providers should be able to attest to their filtering methods and provide evidence (e.g. test results) of their effectiveness. Likewise, if possible, downstream model consumers should include a review of the security claims as part of their security processes before accepting a foundation model for use.
Maliciously modified data – risks and mitigations
Relevant AI Lifecycle stages: 2) Collect & Process Data; 3) Build & Use Model; 4) Verify & Validate; 5) Deploy & Use; 6) Operate & Monitor
Maliciously modified data presents a significant threat to the accuracy and integrity of AI systems. Deliberate manipulation of data can result in inaccurate outcomes, poor decisions, and compromised security. Note that there are also risks associated with unintentional data errors and duplications that can affect the security and performance of AI systems. Challenges like adversarial machine learning threats, statistical bias, and inaccurate information can impact the overall security of AI-driven outcomes.
Risk: Adversarial Machine Learning threats
Adversarial Machine Learning (AML) threats involve intentional, malicious attempts to deceive, manipulate, or disrupt AI systems. [7],[17],[22] Malicious actors employ data poisoning to corrupt the learning process, compromising the integrity of training datasets and leading to unreliable or malicious model behavior. Additionally, malicious actors may introduce adversarial examples into datasets that, while subtle, can evade correct classification, thereby undermining the model’s performance. Furthermore, sensitive information in training datasets can be indirectly extracted through techniques like model inversion4, posing significant data security risks.
Mitigation Strategies:
Anomaly detection: Incorporate anomaly detection algorithms during data pre-processing to identify and remove malicious or suspicious data points before training. These algorithms can recognize statistically deviant patterns in the data, making it possible to isolate and eliminate poisoned inputs.
Data sanitization: Sanitize the training data by applying techniques like data filtering, sampling, and normalization. This helps reduce the impact of outliers, noisy data, and other potentially poisoned inputs, ensuring that models learn from high-quality, representative datasets. Perform sanitization on a regular basis, especially prior to each and every training, fine-tuning, or any other process that adjusts model parameters.
Secure training pipelines: Secure data collection, pre-processing, and training pipelines to prevent malicious actors from tampering with datasets or model parameters.
Ensemble methods / collaborative learning: Implement collaborative learning frameworks that combine an ensemble of multiple, distinct AI models to reach a consensus on output predictions. This approach can help counteract the impact of data poisoning, since malicious inputs may only affect a subset of the collaborative models, allowing the majority to maintain accuracy and reliability.
Data anonymization: Implement anonymization techniques to protect sensitive data attributes, keeping them confidential while allowing AI models to learn patterns and generate accurate predictions.
Risk: Bad data statements
Bad data statements5 [7][23], such as missing metadata, can significantly influence AI data security by introducing data integrity issues that can lead to faulty model performance. Error-free metadata provides valuable contextual information about the data, including its structure, purpose, and collection methods. When metadata is missing, it becomes difficult to interpret data accurately and draw meaningful conclusions. This situation can result in incomplete or inaccurate data representation, compromising AI system performance and reliability. If metadata is modified by a malicious actor, then the security of the AI system is also at risk.
Mitigation strategies:
Metadata management: Implement strong data governance practices to help ensure metadata is well-documented, complete, accurate, and secured.
Metadata validation: Establish data validation processes to check the completeness and consistency of metadata before data is used for AI training.
Data enrichment: Use available resources, such as reference data and trusted third-party data, to supplement missing metadata and improve the overall quality of the training data.
Risk: Statistical bias6
Robust data security and collection practices are key to mitigating statistical bias. Executive Order (EO) 14179 mandates that U.S. government entities “develop AI systems that are free from ideological bias or engineered social agendas.” [25] Note that “an AI system is said to be biased when it exhibits systematically inaccurate behavior.” [26] Statistical bias in AI systems can arise from artifacts present in training data that can lead to artificially slanted or inaccurate outcomes. Sampling biases or biases in data collection can affect the overall outcomes and performance of AI. Left unaddressed, statistical bias can degrade the accuracy and effectiveness of AI systems.
Mitigation strategies:
Regular training data audits: Regularly audit training data to detect, assess, and address potential issues that can result in systematically inaccurate AI systems.
Representative training data: Ensure that training data is representative of the totality of the information relevant to any given topic to reduce the risk of statistical bias. Also ensure that AI data is properly divided into training, development, and evaluation sets without overlap to properly measure statistical bias and other measures of performance.
Edge cases: Identify and mitigate edge cases that can cause models to malfunction.
Test and correct for statistical bias: Create a repository with instances of observed model output bias. Leverage that information to improve training data audits and with reinforcement learning to “undo” some of the measured bias.
Risk: Data poisoning via inaccurate information
One form of data poisoning (sometimes referred to as “disinformation” [27]) involves the intentional insertion of inaccurate or misleading information in AI training datasets, which can negatively impact AI system performance, outcomes, and decision-making processes.
Mitigation strategies:
Remove inaccurate information from training data: Identify and remove inaccurate or misleading information from AI datasets to the extent feasible.
Data provenance and verification: Implement provenance verification mechanisms during data collection to help ensure that only accurate and reliable data is used. This process can include methods such as cross-verification, fact-checking, source analysis, data provenance tracking, and content credentials.
Add more training data: Increasing the amount of non-malicious data makes training more robust against poisoned examples—provided that these poisoned examples are small in number. One way to do this is through data augmentation—the creation of artificial training set samples that are small variations of existing samples. The goal is to “outnumber” the poisoned samples so the model “forgets” them. Note that this mitigation can only be applied during training, and therefore does not apply to an already trained model. [28]
Data quality control: Perform quality control on data including detecting poisoned samples through integrity checks, statistical deviation, or pattern recognition. Proactively implement data quality controls during the training phase to prevent issues before they arise in production.
Risk: Data duplications
Unintended duplicate data elements [7] in training datasets can skew model performance and cause overfitting, reducing the AI model’s ability to generalize across a variety of real-world applications. Duplicates are not always exact; near-duplicates may contain minor differences like formatting, abbreviations, or errors, which makes detecting them more complex. Duplicate data often leads to inaccurate predictions, making the AI system less effective in real-world applications.
Mitigation strategies:
Data deduplication: Implement deduplication techniques (such as fuzzy matching, hashing, clustering, etc.) to carefully identify and handle duplicates and near-duplicates in the data.
Data drift – risks and mitigations
Relevant AI Lifecycle stages: 5) Deploy & Use; 6) Operate & Monitor
Data drift, or distribution shift, refers to changes in the underlying statistical properties of the input data to an operational AI system. Over time, the input data can become significantly different from the data originally used to train the model. [7],[8] Degradation caused by data drift is a natural and expected occurrence, and AI system developers and operators need to regularly update models to maintain accuracy and performance. Data drift ordinarily begins as small, seemingly insignificant degradations in model performance. Left unchecked, the degradation caused by data drift can snowball into substantial reductions in AI system accuracy and integrity that become increasingly difficult to correct.
It is crucial to distinguish between data drift and data poisoning attacks designed to affect an AI model. Continuous monitoring of system accuracy and performance provides important indicators based on the nature of the changes observed. If the changes are slow and gradual over time, it is more likely that the model is experiencing data drift. If the changes are abrupt and dramatic in one or more dimensions, it is more likely that an actor is trying to compromise the model. Cyber compromises often aim to manipulate the model’s performance quickly and significantly, leading to abrupt changes in the input data or model outputs.
AI system operators and developers should employ a wide range of techniques for detecting and mitigating data drift, including data preprocessing, increasing dataset coverage of real-world scenarios, and adopting robust training and adaptation strategies. [30] Packages that automate dataset loading assist AI system developers in creating application-specific detection and mitigation techniques for data drift.
There are many potential causes of data drift, including:
A change in the upstream data pipeline not represented in the model training data (e.g., the units of a particular data element change from miles to kilometers)
The introduction of completely new data elements that the model had not previously seen (e.g., a new type of malware not recognized in the ML layer of an anti-virus product)
A change in the context of how inputs and outputs are related (e.g., a change in organizational structure due to a merger or acquisition could lead to new data access patterns that might be misinterpreted as security threats by an AI system)
The data associated with a given AI model should be regularly checked for any updates to help ensure the model still predicts as expected. [7],[8],[9] The interval for this update and check will depend on the particular AI system and application. For example, in high-stakes applications such as healthcare, early detection and mitigation of data drift are critical prior to patient impact. Thus, continuous monitoring of model performance with additional direct analysis of the input data is important in such applications. [30]
Mitigation strategies:
Data management: Employ a data management strategy in keeping with the best practices in this CSI to help ensure that it is easy to add and track new data elements for model training and adaptation. This management strategy enables identification of data elements causing drift for appropriate mitigation or action.
Data-quality testing: AI system developers should use data-quality assessment tools to assist in selecting and filtering data used for model training or adaptation. Understanding the current dataset and its impact on model behavior is critical to detecting data drift.
Input and output monitoring: Monitor the AI system inputs and outputs to verify the model is performing as expected. [9] Regularly update your model using current data. Utilize meaningful statistical methods that measure expected dataset metrics and compare the distribution of the training data to the test data to help determine if data drift is occurring. [7]
Data management tools and methods are currently an active area of research. However, data drift can be mitigated by incorporating application-specific data management protocols that include: continuous monitoring, retraining (regularly incorporating the latest data into the models), data cleansing (correcting errors or inconsistencies in the data), and using ensemble models (combining predictions of multiple models). Incorporation of a data management framework into the design of AI systems from the beginning is essential for improving the overall integrity and security posture. [31]
Conclusion
Data security is of paramount importance when developing and operating AI systems. As organizations in various sectors rely more and more on AI-driven outcomes, data security becomes crucial for maintaining accuracy, reliability, and integrity. The guidance provided in this CSI outlines a robust approach to securing AI data and addressing the risks associated with the data supply chain, malicious data, and data drift.
Data security is an ever-evolving field, and continuous vigilance and adaptation are key to staying ahead of emerging threats and vulnerabilities. The best practices presented here encourage the highest standards of data security in AI while helping ensure the accuracy and integrity of AI-driven outcomes. By adopting these best practices and risk mitigation strategies, organizations can fortify their AI systems against potential threats and safeguard sensitive, proprietary, and mission critical data used in the development and operation of their AI systems.
References
1 In this document, Artificial Intelligence (AI) has the meaning set forth in 15 U.S.C. 9401(3): “… a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations, or decisions influencing real or virtual environments. AI systems use machine- and human-based inputs to: (A) Perceive real and virtual environments; (B) Take these perceptions and turn them into models through analysis in an automated manner; and (C) Use model inference to formulate options for information or action.”
2 Data integrity is defined by the IC Data Management Lexicon [1] as “The degree to which data can be trusted due to its provenance, pedigree, lineage and conformance with all business rules regarding its relationship with other data. In the context of data movement, this is the degree to which data has verifiably not been changed unexpectedly by a person or NPE.”
3 The term data consumers is defined as technical personnel (e.g. data scientists, engineers) who make use of data that they themselves did not produce or annotate to build and/or operate AI systems.
4 Model inversion refers to the process by which an attacker analyzes the output patterns of an AI system to reverse-engineer and uncover details about the training dataset, such as individual data points or patterns. This process can potentially expose confidential or proprietary information from the data that was used to train the AI models.
5 “A data statement is a characterization of a dataset that provides context to allow developers and users to better understand how experimental results might generalize, how software might be appropriately deployed, and what biases might be reflected in systems built on the software.” [23]
6 “In technical systems, bias is most commonly understood and treated as a statistical phenomenon. Bias is an effect that deprives a statistical result of representativeness by systematically distorting it, as distinct from random error, which may distort on any one occasion but balances out on the average.” [26],[32]
Works cited
[1] Office of the Director of National Intelligence. The Intelligence Community Data Management Lexicon. 2024. https://dni.gov/files/ODNI/documents/IC_Data_Management_Lexicon.pdf [2] National Security Agency et al. Deploying AI Systems Securely: Best Practices for Deploying Secure and Resilient AI Systems. 2024. https://media.defense.gov/2024/Apr/15/2003439257/-1/-1/0/CSI-DEPLOYING-AI-SYSTEMS-SECURELY.PDF [3] National Institute of Standards and Technology (NIST). NIST AI 100-1: Artificial Intelligence Risk Management Framework (AI RMF 1.0). 2023. https://doi.org/10.6028/NIST.AI.100-1 [4] NIST. NIST Special Publication 800-37 Rev. 2: Guide for Applying the Risk Management Framework to Federal Information Systems. 2018. https://doi.org/10.6028/NIST.SP.800-37r2 [5] NIST. Federal Information Processing Standards Publication (FIPS) 204: Module-Lattice-Based Digital Signature Standard. 2024. https://doi.org/10.6028/NIST.FIPS.204 [6] NIST. FIPS 205: Stateless Hash-Based Digital Signature Standard. 2024. https://doi.org/10.6028/NIST.FIPS.205 [7] Bommasani, R. et al. On the Opportunities and Risks of Foundation Models. arXiv:2108.07258v3. 2022. https://arxiv.org/abs/2108.07258v3 [8] Securing Artificial Intelligence (SAI); Data Supply Chain Security. ESTI GR SAI 002 V1.1.1. 2021. https://etsi.org/deliver/etsi_gr/SAI/001_099/002/01.01.01_60/gr_SAI002v010101p.pdf [9] National Cyber Security Centre et al. Guidelines for Secure AI System Development. 2023. https://www.ncsc.gov.uk/files/Guidelines-for-secure-AI-system-development.pdf [10] NIST. NIST Special Publication 800-207: Zero Trust Architecture. 2020. https://doi.org/10.6028/NIST.SP.800-207 [11] NIST. NIST IR 8496 ipd: Data Classification Concepts and Considerations for Improving Data Protection. 2023. https://doi.org/10.6028/NIST.IR.8496.ipd [12] Cybersecurity and Infrastructure Security Agency (CISA), NSA, and NIST. Quantum-Readiness: Migration to Post-Quantum Cryptography. 2023. https://www.cisa.gov/resources-tools/resources/quantum-readiness-migration-post-quantum-cryptography [13] NIST. FIPS 203: Module-Lattice-Based Key-Encapsulation Mechanism Standard. 2024. https://doi.org/10.6028/NIST.FIPS.203 [14] NIST. NIST SP 800-52 Rev. 2: Guidelines for the Selection, Configuration, and Use of Transport Layer Security (TLS) Implementations. 2019. https://doi.org/10.6028/NIST.SP.800-52r2 [15] NIST. FIPS 140-3, Security Requirements for Cryptographic Modules. 2019. https://doi.org/10.6028/NIST.FIPS.140-3 [16] NIST. FIPS 140-2, Security Requirements for Cryptographic Modules. 2001. https://doi.org/10.6028/NIST.FIPS.140-2 [17] NIST. NIST AI 100-2e2023: Trustworthy and Responsible AI, Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations. 2024. https://doi.org/10.6028/NIST.AI.100-2e2023 [18] Adak, M. F., Kose, Z. N., & Akpinar, M. Dynamic Data Masking by Two-Step Encryption. In 2023 Innovations in Intelligent Systems and Applications Conference (ASYU) (pp. 1-5). IEEE. 2023 https://doi.org/10.1109/ASYU58738.2023.10296545 [19] Kairouz, P. et al. Advances and Open Problems in Federated Learning. Foundations and Trends in Machine Learning 14 (1-2): 1-210. arXiv:1912.04977. 2021. https://arxiv.org/abs/1912.04977 [20] NIST. NIST SP 800-88 Rev. 1: Guidelines for Media Sanitization. 2014. https://doi.org/10.6028/NIST.SP.800-88r1 [21] NIST. NIST Special Publication 800-3 Rev. 2: Risk Management Framework for Information Systems and Organizations: A System Life Cycle Approach for Security and Privacy. 2018. https://doi.org/10.6028/NIST.SP.800-37r2 [22] U.S. Department of Homeland Security. Preparedness Series June 2023: Risks and Mitigation Strategies for Adversarial Artificial Intelligence Threats: A DHS S&T Study. 2023. https://www.dhs.gov/sites/default/files/2023-12/23_1222_st_risks_mitigation_strategies.pdf [23] Bender, E. M., & Friedman, B. Data Statements for Natural Language Processing: Toward Mitigating System Bias and Enabling Better Science. Transactions of the Association for Computational Linguistics (TACL) 6, 587–604. 2018. https://doi.org/10.1162/tacl_a_00041 [24] NSA et al. Content Credentials: Strengthening Multimedia Integrity in the Generative AI Era. 2025. https://media.defense.gov/2025/Jan/29/2003634788/-1/-1/0/CSI-CONTENT-CREDENTIALS.PDF [25] Executive Order (EO) 14179: “Removing Barriers to American Leadership in Artificial Intelligence” https://www.federalregister.gov/executive-order/14179 [26] NIST. NIST Special Publication 1270: Framework for Identifying and Managing Bias in Artificial Intelligence. 2023. https://doi.org/10.6028/NIST.SP.1270 [27] NIST. NIST AI 600-1: Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile. 2023. https://doi.org/10.6028/NIST.AI.600-1 [28] Open Web Application Security Project (OWASP). AI Exchange. #Moretraindata. https://owaspai.org/goto/moretraindata/ [29] Carlini, N. et al. Poisoning Web-Scale Training Datasets is Practical. arXiv:2302.10149. 2023. https://arxiv.org/abs/2302.10149 [30] Kore, A., Abbasi Bavil, E., Subasri, V., Abdalla, M., Fine, B., Dolatabadi, E., & Abdalla, M. Empirical Data Drift Detection Experiments on Real-World Medical Image Data. Nature Communications 15, 1887. 2024. https://doi.org/10.1038/s41467-024-46142-w [31] NIST. NIST Special Publication 800-208: Recommendation for Stateful Hash-Based Signature Schemes. 2020. https://doi.org/10.6028/NIST.SP.800-208 [32] The Organisation for Economic Cooperation and Development (OECD). Glossary of statistical terms. 2008. https://doi.org/10.1787/9789264055087-en [33] NIST. NIST SP 800-53 Rev. 5: Security and Privacy Controls for Information Systems and Organizations. 2020. https://doi.org/10.6028/NIST.SP.800-53r5 [34] OWASP. AI Exchange. How to select relevant threats and controls? risk analysis. https://owaspai.org/goto/riskanalysis/
Disclaimer of Endorsement
The information and opinions contained in this document are provided “as is” and without any warranties or guarantees. Reference herein to any specific commercial products, process, or service by trade name, trademark, manufacturer, or otherwise, does not constitute or imply its endorsement, recommendation, or favoring by the United States Government, and this guidance shall not be used for advertising or product endorsement purposes.
Purpose
This document was developed in furtherance of the authoring organizations’ cybersecurity missions, including their responsibilities to identify and disseminate threats, and to develop and issue cybersecurity specifications and mitigations. This information may be shared broadly to reach all appropriate stakeholders.
Notice of Generative AI Use
Generative AI technology was carefully and responsibly used in the development of this document. The authors maintain ultimate responsibility for the accuracy of the information provided herein.
Contact
U.S. Organizations
National Security Agency
Cybersecurity Report Feedback: CybersecurityReports@nsa.gov
Defense Industrial Base Inquiries and Cybersecurity Services: DIB_Defense@cyber.nsa.gov
Media Inquiries / Press Desk: NSA Media Relations: 443-634-0721, MediaRelations@nsa.gov
Australian organizations
Visit cyber.gov.au/report or call 1300 292 371 (1300 CYBER1) to report cybersecurity incidents and vulnerabilities.
New Zealand organizations
For general enquiries, contact info@ncsc.govt.nz
Executive summary
This Cybersecurity Information Sheet (CSI) provides essential guidance on securing data used in artificial intelligence (AI) and machine learning (ML) systems. It also highlights the importance of data security in ensuring the accuracy and integrity of AI outcomes and outlines potential risks arising from data integrity issues in various stages of AI development and deployment.
This CSI provides a brief overview of the AI system lifecycle and general best practices to secure data used during the development, testing, and operation of AI-based systems. These best practices include the incorporation of techniques such as data encryption, digital signatures, data provenance tracking, secure storage, and trust infrastructure. This CSI also provides an in-depth examination of three significant areas of data security risks in AI systems: data supply chain, maliciously modified (“poisoned”) data, and data drift. Each section provides a detailed description of the risks and the corresponding best practices to mitigate those risks.
This guidance is intended primarily for organizations using AI systems in their operations, with a focus on protecting sensitive, proprietary, or mission critical data. The principles outlined in this information sheet provide a robust foundation for securing AI data and ensuring the reliability and accuracy of AI-driven outcomes.
This document was authored by the National Security Agency’s Artificial Intelligence Security Center (AISC), the Cybersecurity and Infrastructure Security Agency (CISA), the Federal Bureau of Investigation (FBI), the Australian Signals Directorate’s Australian Cyber Security Centre (ASD’s ACSC), the New Zealand’s Government Communications Security Bureau’s National Cyber Security Centre (NCSC-NZ), and the United Kingdom’s National Cyber Security Centre (NCSC-UK).
The goals of this guidance are to:
Raise awareness of the potential risks related to data security in the development, testing, and deployment of AI systems;
Provide guidance and best practices for securing AI data across various stages of the AI lifecycle, with an in-depth description of the three aforementioned significant areas of data security risks; and
Establish a strong foundation for data security in AI systems by promoting the adoption of robust data security measures and encouraging proactive risk mitigation strategies.
The data resources used during the development, testing, and operation of an AI1 system are a critical component of the AI supply chain; therefore, the data resources must be protected and secured. In its Data Management Lexicon, [1] the Intelligence Community (IC) defines Data Security as “The ability to protect data resources from unauthorized discovery, access, use, modification, and/or destruction…. Data Security is a component of Data Protection.”
Data security is paramount in the development and deployment of AI systems. Therefore, it is a key component of strategies developed to safeguard and manage the overall security of AI-based systems. Successful data management strategies must ensure that the data has not been tampered with at any point throughout the entire AI system lifecycle; is free from malicious, unwanted, and unauthorized content; and does not have unintentional duplicative or anomalous information. Note that AI data security depends on robust, fundamental cybersecurity protection for all datasets used in designing, developing, deploying, operating, and maintaining AI systems and the ML models that enable them.
Audience and scope
This CSI outlines potential risks in AI systems stemming from data security issues that arise during different phases of an AI deployment, and it introduces recommended protocols to mitigate these risks. This guidance builds upon the NSA’s joint guidance on Deploying AI Systems Securely [2] and delves deeper into securing the data used to train and operate AI-based systems. This guidance is primarily developed for organizations that use AI systems in their day-to-day operations, including the Defense Industrial Base (DIB), National Security System (NSS) owners, Federal Civilian Executive Branch (FCEB) agencies, and critical infrastructure owners and operators. Implementing these mitigations can help secure AI-enabled systems and protect proprietary, sensitive, and/or mission critical data.
Securing data throughout the AI system lifecycle
Data security is a critical enabler that spans all phases of the AI system lifecycle. ML models learn their decision logic from data, so an attacker who can manipulate the data can also manipulate the logic of an AI-based system. In the AI Risk Management Framework (RMF) [3], the National Institute of Standards and Technology (NIST) defines six major stages in the lifecycle of AI systems, starting from Plan & Design and progressing all the way to Operate & Monitor. The following table highlights relevant data security factors for each stage of the AI lifecycle:
Table 1: The AI System Lifecycle with key dimensions, necessary ongoing assessments, focus areas for data security, and particular data security risks covered in this CSI. [3]
Particular Data Security Risks Covered in this CSI
1) Plan & Design
Application Context
Audit & Impact Assessment
Incorporating data security measures from inception, designing robust security protocols, threat modeling, and including privacy by design
Data supply chain
2) Collect & Process Data
Data & Input
Internal & External Validation
Ensuring data integrity, authenticity, encryption, access controls, data minimization, anonymization, and secure data transfer
Data supply chain, maliciously modified data
3) Build & Use Model
AI Model
Model Testing
Protecting data from tampering, ensuring data quality and privacy (including differential privacy and secure multi-party computation when appropriate and possible), securing model training, and operating environments
Data supply chain, maliciously modified data
4) Verify & Validate
AI Model
Model Testing
Performing comprehensive security testing, identifying and mitigating risks, validating data integrity, adversarial testing, and formal verification when appropriate and possible
Data supply chain, maliciously modified data
5) Deploy & Use
Task & Output
Integration, Compliance Testing, Validation
Implementing strict access controls, zero-trust infrastructure, secure data transmission and storage, secure API endpoints, and monitoring for anomalous behavior
Data supply chain, maliciously modified data, data drift
6) Operate & Monitor
Application Context
Audit & Impact Assessment
Conducting continuous risk assessments, monitoring for data breaches, deleting data securely, complying with regulations, incident response planning, and regular security auditing
Data supply chain, maliciously modified data, data drift
Throughout the AI system lifecycle, securing data is paramount to maintaining information integrity and system reliability. Starting with the initial Plan & Design phase, carefully plan data protection measures to provide proactive mitigations of potential risks. In the Collect & Process Data phase, data must be carefully analyzed, labeled, sanitized, and protected from breaches and tampering. Securing data in the Build & Use Model phase helps ensure models are trained on reliably sourced, accurate, and representative information. In the Verify & Validate phase, comprehensive and thorough testing of AI models, derived from training data, can identify security flaws and enable their mitigation.
Note that Verification & Validation is necessary each time new data or user feedback is introduced into the model; therefore, that data also needs to be handled with the same security standards as AI training data. Implementing strict access controls protects data from unauthorized access, especially in the Deploy & Use phase. Lastly, continuous data risk assessments in the Operate & Monitor phase are necessary to adapt to evolving threats. Neglecting these practices can lead to data corruption, compromised models, data leaks, and non-compliance, emphasizing the critical importance of robust data security at every phase.
Best practices to secure data for AI-based systems
The following list contains recommended practical steps that system owners can take to better protect the data used to build and operate their AI-based systems, whether running on premises or in the cloud. For more details on general cybersecurity best practices, see also NIST SP 800-53, “Security and Privacy Controls for Information Systems and Organizations.” [33]
1. Source reliable data and track data provenance Verify data sources use trusted, reliable, and accurate data for training and operating AI systems. To the extent possible, only use data from authoritative sources. Implement provenance tracking to enable the tracing of data origins, and log the path that data follows through an AI system. [7],[8],[9] Incorporate a secure provenance database that is cryptographically signed and maintains an immutable, append-only ledger of data changes. This facilitates data provenance tracking, helps identify sources of maliciously modified data, and helps ensure that no single entity can undetectably manipulate the data. 2. Verify and maintain data integrity during storage and transport Maintaining data integrity2 is an essential component to preserve the accuracy, reliability, and trustworthiness of AI data. [4] Use checksums and cryptographic hashes to verify that data has not been altered or tampered with during storage or transmission. Generating such unique codes for AI datasets enables the detection of unauthorized changes or corruption, safeguarding the information’s authenticity.
3. Employ digital signatures to authenticate trusted data revisions Digital signatures help ensure data integrity and prevent tampering by third parties. Adopt quantum-resistant digital signature standards [5][6] to authenticate and verify datasets used during AI model training, fine tuning, alignment, reinforcement learning from human feedback (RLHF), and/or other post-training processes that affect model parameters. Original versions of the data should be cryptographically signed, and any subsequent data revisions should be signed by the person who made the change. Organizations are encouraged to use trusted certificate authorities to verify this process. 4. Leverage trusted infrastructure Use a trusted computing environment that leverages Zero Trust architecture. [10] Provide secure enclaves for data processing and keep sensitive information protected and unaltered during computations. This approach fosters a secure foundation for data privacy and security in AI data workflows by isolating sensitive operations and mitigating risks of tampering. Trusted computing infrastructure supports the integrity of data processes, reduces risks associated with unverified or altered data, and ultimately creates a more robust and transparent AI ecosystem. Trusted environments are essential for AI applications where data accuracy directly impacts their decision-making processes. 5. Classify data and use access controls Categorize data using a classification system based on sensitivity and required protection measures. [11] This process enables organizations to apply appropriate security controls to different data types. Classifying data enables the enforcement of robust protection measures like stringent encryption and access controls. [33] In general, the output of AI systems should be classified at the same level as the input data (rather than creating a separate set of guardrails). 6. Encrypt data Adopt advanced encryption protocols proportional to the organizational data protection level. This includes securing data at rest, in transit, and during processing. AES-256 encryption is the de facto industry standard and is considered resistant to quantum computing threats. [12],[13] Use protocols, such as TLS with AES-256 or post-quantum encryption, for data in transit. Refer to NIST SP 800-52r2, “Guidelines for the Selection, Configuration, and Use of Transport Layer Security (TLS) Implementations” [14] for more details. 7. Store data securely Store data in certified storage devices that enforce NIST FIPS 140-3 [15] compliance, ensuring that the cryptographic modules used to encrypt the data provide high-level security against advanced intrusion attempts. Note that Security Level 3 (defined in NIST FIPS 140-2 [16]) provides robust data protection; however, evaluate and determine the appropriate level of security based on organizational needs and risk assessments. 8. Leverage privacy-preserving techniques There are several privacy-preserving techniques [17] that can be leveraged for increased data security. Note that there may be practical limitations to their implementation due to computational cost.
Data depersonalization techniques (e.g., data masking [18]) involve replacing sensitive data with inauthentic but realistic information that maintains the distributions of values throughout the dataset. This enables AI systems to utilize datasets without exposing sensitive information, reducing the impact of data breaches and supporting secure data sharing and collaboration. When possible, use data masking to facilitate AI model training and development without compromising sensitive information (e.g., personally identifiable information [PII]).
Differential privacy is a framework that provides a mathematical guarantee quantifying the level of privacy of a dataset or query. It requires a pre-specified privacy budget for the level of noise added to the data, but there are tradeoffs between protecting the training data from membership inference techniques and target task accuracy. Refer to [17] for further details.
Decentralized learning techniques (e.g., federated learning [19]) permit AI system training over multiple local datasets with limited sharing of data among local instances. An aggregator model incorporates the results of the distributed models, limiting access on the local instance to the larger training dataset. Secure multi-party computation is recommended for training and inferencing processes.
9. Delete data securely Prior to repurposing or decommissioning any functional drives used for AI data storage and processing, erase them using a secure deletion method such as cryptographic erase, block erase, or data overwrite. Refer to NIST SP 800-88, “Guidelines for Media Sanitization,” [20] for guidance on appropriate deletion methods. 10. Conduct ongoing data security risk assessments Conduct ongoing risk assessments using industry-standard frameworks, such as the NIST SP 800-3r2, Risk Management Framework (RMF) [4][21], and the NIST AI 100-1, Artificial Intelligence RMF [3]. These assessments should evaluate the AI data security landscape, identify risks, and prioritize actions to minimize security incidents. Continuously improve data security measures to keep pace with evolving threats and vulnerabilities, learn from security incidents, stay up to date with emerging technologies, and maintain a robust security posture.
Data supply chain – risks and mitigations
Relevant AI Lifecycle stages: 1) Plan & Design; 2) Collect & Process Data; 3) Build & Use Model; 4) Verify & Validate; 5) Deploy & Use; 6) Operate & Monitor
Developing and deploying secure and reliable AI systems requires understanding potential risks and methods of introducing inaccurate or maliciously modified (a.k.a. “poisoned”) data into the system. In short, the security of AI systems depends on thorough verification of training data and proactive measures to detect and prevent the introduction of inaccurate material.
Threats can stem from large-scale data collected and curated by third parties, as well as from data that is not sufficiently protected after ingestion. Data collected and/or curated by a third party may contain inaccurate information, either unintentionally or through malicious intent. Inaccurate material can compromise not only models trained using that data, but also any additional models that rely on compromised models as a foundation.
It is crucial, therefore, to verify the integrity of the training data used when building an AI system. Organizations that utilize third-party data must take appropriate measures to ensure that: 1) the data is not compromised upon ingestion; and 2) the data cannot be compromised after it has been incorporated into the AI system. As such, both data curators and data consumers should follow the best practices for digital signatures, data integrity, and data provenance that are described in detail above.
The use of web-scale databases includes all of the risks outlined earlier, and one cannot simply assume that these datasets are clean, accurate, and free of malicious content. Third-party models trained on web-scraped data used to train a model for downstream tasks could also affect the model’s learning process and result in behavior that was unintended by the AI system designer.
From the moment data is ingested for use with AI systems, the data acquirer must secure it against insider threats and malicious network activity to prevent unauthorized modification.
Mitigation strategies:
Dataset verification: Before ingest, the consumer or curator should verify, as much as possible, that the dataset to be ingested is free of malicious or inaccurate material. Any detected abnormalities should be addressed, and suspicious data should not be stored. The dataset verification process should include a digital signature of the dataset at time of ingestion.
Content credentials: Use content credentials to track the provenance of media and other data. Content credentials are “metadata that are secured cryptographically and allow creators the ability to add information about themselves or their creative process, or both, directly to media content…. Content Credentials securely bind essential metadata to a media file that can track its origin(s), any edits made, and/or what was used to create or modify the content…. This metadata alone does not allow a consumer to determine whether a piece of content is ‘true,’ but rather provides contextual information that assists in determining the authenticity of the content.” [24]
Foundation model assurances: In the case where a consumer is not ingesting a dataset but a foundation model trained by another party, the developers of the foundation model need to be able to provide assurances regarding the data and sources used and certify that their training data did not contain any known compromised data. Take care to track the training data used in various model lineages. Exercise caution before using a model without such assurances.
Require certification: Data consumers should strongly consider requiring a formal certification from dataset and model providers, attesting that their systems are free from known compromised data before using third-party data and/or foundation models.
Secure storage: After ingest, data needs to be stored in a database that adheres to the best practices for digital signatures, data integrity, and data provenance that are described in detail above. Note that an append-only cryptographically signed database should be used where feasible, but there may be a need to delete older material that is no longer relevant. Each time a data element is updated (e.g., resized, cropped, flipped, etc.) for augmentation purposes in a non-temporary fashion, then the updated data should be stored as a new entry with documented changes. The database’s certificate should be verified at the time the database is accessed for a training run. If the database does not pass the certificate check, abort the training and conduct a comprehensive database audit to discover any data modifications.
2023 investigations by various industry professionals explored low-resource methods for introducing malicious or inaccurate material into web-scale datasets, and potential strategies to mitigate this risk. [29] These vulnerabilities depend on the fact that curators or collectors do not have control over the data, as seen in cases of datasets curated by third parties (e.g., LAION) or datasets that are continually updated and released (e.g., Wikipedia).
Risk: Curated web-scale datasets
Curated AI datasets (e.g., LAION-2B or COYO-700M) are vulnerable to a type of technique known as split-view poisoning. This risk arises because these datasets often contain data hosted on domains that may have expired or are no longer actively maintained by their original owners. In such cases, anyone who purchases these expired domains gains control over the content hosted on them. This situation creates an opportunity for malicious actors to modify or replace the data that the curated list points to, potentially introducing inaccurate or misleading information into the dataset. In many instances, it is possible to purchase enough control of a dataset to conduct effective poisoning for roughly $1,000 USD. In some cases, effective techniques can cost as little as $60 USD (e.g., COYO-700M), making this a viable threat from low-resource threat actors.
Mitigation strategies:
Raw data hashes: Data curators should attach a cryptographic hash to all raw data referenced in the dataset. This will enable follow-on data consumers to verify that the data has not changed since it was added to the list.
Hash verification: Data consumers should incorporate a hash check at time of download in order to detect any changes made to it, and the downloader should discard any data that does not pass the hash check.
Periodic checks: Curators should periodically scrape the data themselves to verify that the data has not been modified. If any changes are detected, the curator should take appropriate steps to ensure the data’s integrity.
Verifying data: Curators should verify that any changed data is clean and free from inaccurate or malicious material. If the content of the data has been altered in any way, the curator should either remove it from their list or flag it for further review.
Certification by curators: Since the data supply chain begins with the curators, the certification process must start there as well. To the best of their ability, curators should be able to certify that, at the time of publication, the dataset contains no malicious or inaccurate material.
Risk: Collected web-scale datasets
Collected web-scale datasets (e.g., Wikipedia) are vulnerable to frontrunning poisoning techniques. Frontrunning poisoning occurs when an actor injects malicious examples in a short time window before websites with crowd-sourced content collect a snapshot of their data. Wikipedia in particular conducts twice-monthly snapshots of their data and publishes these snapshots for people to download. Since the snapshots happen at known times, it is possible for malicious actors to edit pages close enough to the snapshot time so that malicious edits will be captured and published before they can be discovered and corrected. Industry analysis demonstrated potential malicious actors would be able to successfully poison as much as 6.5% of Wikipedia. [29]
Mitigation strategies:
Test & verify web-scale datasets: Be cautious when using web-scale datasets that are vulnerable to frontrunning poisoning. Check that the data hasn’t been manipulated, and only use snapshots verified by a trusted party.
(For web-scale data collectors) Randomize or lengthen snapshots: Collectors such as Wikipedia should defend against actors making malicious edits ahead of a planned snapshot by:
Randomizing the snapshot order.
Freezing edits to content long enough for edits to go through review before releasing the snapshot.
These mitigations focus on increasing the amount of time a malicious actor must maintain control of the data for it to be included in the published snapshot. Any reasonable methods that increase the time a malicious actor must control the data are also recommended.
Note that these mitigations are limited since they rely on trusted curators who can detect malicious edits. It is more difficult to defend against subtle edits (e.g., attempts to insert hidden watermarks) that appear valid to human reviewers but impact machine understanding.
Risk: Web-crawled datasets
Web-crawled datasets present a unique intersection of the risks discussed above. Since web-crawled datasets are substantially less curated than other web-scale datasets, they bring increased risk. There are no trusted curators to detect malicious edits. There are no original curated views to which cryptographic hashes can be attached. The unfortunate reality is that “updates to a web page have no realistic bound on the delta between versions which might act as a signal for attaching trust.” [29]
Mitigation strategies:
Consensus approaches: Data consumers using web-crawled datasets should rely on consensus-based approaches, since notional determinations of which domains to trust are ad-hoc and insufficient. For example, an AI developer could choose to only trust an image-caption pair when it appears on many different websites to reduce susceptibility to poisoning techniques, since a malicious actor would have to poison a sufficiently large number of websites to be successful.
Data curation: Ultimately, it is incumbent on organizations to ensure malicious or inaccurate material is not present in the data they use. If an organization does not have resources to conduct the necessary due diligence, then the use of web-crawled datasets is not recommended until some sort of trust infrastructure can be implemented.
Final note on web-scale datasets and data poisoning
Both split-view and frontrunning poisoning are reasonably straightforward for a malicious actor to execute, since they do not require particularly sophisticated methodology. These poisoning techniques should be considered viable threats by anyone looking to incorporate web-scale data into their AI systems. The danger here comes not only from directly using compromised data, but also from using models which may themselves have been trained on compromised data.
Ultimately, data poisoning must be addressed from a supply chain perspective by those who train and fine-tune AI models. Proper supply chain integrity and security management (i.e., selecting reliable model providers and verifying the legitimacy of the models used) can reduce the risk of data poisoning and system compromise. The most reliable providers are those who assure that they do everything possible to prevent the influence and distribution of poisoned data and models. [34]
Every effort must be made by those building foundation models to filter out malicious and inaccurate data. Foundation models are evolving rapidly, and filtering out inaccurate, unauthorized, and malicious training data is an active area of research, particularly at web-scale. As such, is currently impractical to prescribe precise methods for doing so; it is a best-effort endeavor. Ideally, data curators and foundation model providers should be able to attest to their filtering methods and provide evidence (e.g. test results) of their effectiveness. Likewise, if possible, downstream model consumers should include a review of the security claims as part of their security processes before accepting a foundation model for use.
Maliciously modified data – risks and mitigations
Relevant AI Lifecycle stages: 2) Collect & Process Data; 3) Build & Use Model; 4) Verify & Validate; 5) Deploy & Use; 6) Operate & Monitor
Maliciously modified data presents a significant threat to the accuracy and integrity of AI systems. Deliberate manipulation of data can result in inaccurate outcomes, poor decisions, and compromised security. Note that there are also risks associated with unintentional data errors and duplications that can affect the security and performance of AI systems. Challenges like adversarial machine learning threats, statistical bias, and inaccurate information can impact the overall security of AI-driven outcomes.
Risk: Adversarial Machine Learning threats
Adversarial Machine Learning (AML) threats involve intentional, malicious attempts to deceive, manipulate, or disrupt AI systems. [7],[17],[22] Malicious actors employ data poisoning to corrupt the learning process, compromising the integrity of training datasets and leading to unreliable or malicious model behavior. Additionally, malicious actors may introduce adversarial examples into datasets that, while subtle, can evade correct classification, thereby undermining the model’s performance. Furthermore, sensitive information in training datasets can be indirectly extracted through techniques like model inversion4, posing significant data security risks.
Mitigation Strategies:
Anomaly detection: Incorporate anomaly detection algorithms during data pre-processing to identify and remove malicious or suspicious data points before training. These algorithms can recognize statistically deviant patterns in the data, making it possible to isolate and eliminate poisoned inputs.
Data sanitization: Sanitize the training data by applying techniques like data filtering, sampling, and normalization. This helps reduce the impact of outliers, noisy data, and other potentially poisoned inputs, ensuring that models learn from high-quality, representative datasets. Perform sanitization on a regular basis, especially prior to each and every training, fine-tuning, or any other process that adjusts model parameters.
Secure training pipelines: Secure data collection, pre-processing, and training pipelines to prevent malicious actors from tampering with datasets or model parameters.
Ensemble methods / collaborative learning: Implement collaborative learning frameworks that combine an ensemble of multiple, distinct AI models to reach a consensus on output predictions. This approach can help counteract the impact of data poisoning, since malicious inputs may only affect a subset of the collaborative models, allowing the majority to maintain accuracy and reliability.
Data anonymization: Implement anonymization techniques to protect sensitive data attributes, keeping them confidential while allowing AI models to learn patterns and generate accurate predictions.
Risk: Bad data statements
Bad data statements5 [7][23], such as missing metadata, can significantly influence AI data security by introducing data integrity issues that can lead to faulty model performance. Error-free metadata provides valuable contextual information about the data, including its structure, purpose, and collection methods. When metadata is missing, it becomes difficult to interpret data accurately and draw meaningful conclusions. This situation can result in incomplete or inaccurate data representation, compromising AI system performance and reliability. If metadata is modified by a malicious actor, then the security of the AI system is also at risk.
Mitigation strategies:
Metadata management: Implement strong data governance practices to help ensure metadata is well-documented, complete, accurate, and secured.
Metadata validation: Establish data validation processes to check the completeness and consistency of metadata before data is used for AI training.
Data enrichment: Use available resources, such as reference data and trusted third-party data, to supplement missing metadata and improve the overall quality of the training data.
Robust data security and collection practices are key to mitigating statistical bias. Executive Order (EO) 14179 mandates that U.S. government entities “develop AI systems that are free from ideological bias or engineered social agendas.” [25] Note that “an AI system is said to be biased when it exhibits systematically inaccurate behavior.” [26] Statistical bias in AI systems can arise from artifacts present in training data that can lead to artificially slanted or inaccurate outcomes. Sampling biases or biases in data collection can affect the overall outcomes and performance of AI. Left unaddressed, statistical bias can degrade the accuracy and effectiveness of AI systems.
Mitigation strategies:
Regular training data audits: Regularly audit training data to detect, assess, and address potential issues that can result in systematically inaccurate AI systems.
Representative training data: Ensure that training data is representative of the totality of the information relevant to any given topic to reduce the risk of statistical bias. Also ensure that AI data is properly divided into training, development, and evaluation sets without overlap to properly measure statistical bias and other measures of performance.
Edge cases: Identify and mitigate edge cases that can cause models to malfunction.
Test and correct for statistical bias: Create a repository with instances of observed model output bias. Leverage that information to improve training data audits and with reinforcement learning to “undo” some of the measured bias.
Risk: Data poisoning via inaccurate information
One form of data poisoning (sometimes referred to as “disinformation” [27]) involves the intentional insertion of inaccurate or misleading information in AI training datasets, which can negatively impact AI system performance, outcomes, and decision-making processes.
Mitigation strategies:
Remove inaccurate information from training data: Identify and remove inaccurate or misleading information from AI datasets to the extent feasible.
Data provenance and verification: Implement provenance verification mechanisms during data collection to help ensure that only accurate and reliable data is used. This process can include methods such as cross-verification, fact-checking, source analysis, data provenance tracking, and content credentials.
Add more training data: Increasing the amount of non-malicious data makes training more robust against poisoned examples—provided that these poisoned examples are small in number. One way to do this is through data augmentation—the creation of artificial training set samples that are small variations of existing samples. The goal is to “outnumber” the poisoned samples so the model “forgets” them. Note that this mitigation can only be applied during training, and therefore does not apply to an already trained model. [28]
Data quality control: Perform quality control on data including detecting poisoned samples through integrity checks, statistical deviation, or pattern recognition. Proactively implement data quality controls during the training phase to prevent issues before they arise in production.
Risk: Data duplications
Unintended duplicate data elements [7] in training datasets can skew model performance and cause overfitting, reducing the AI model’s ability to generalize across a variety of real-world applications. Duplicates are not always exact; near-duplicates may contain minor differences like formatting, abbreviations, or errors, which makes detecting them more complex. Duplicate data often leads to inaccurate predictions, making the AI system less effective in real-world applications.
Mitigation strategies:
Data deduplication: Implement deduplication techniques (such as fuzzy matching, hashing, clustering, etc.) to carefully identify and handle duplicates and near-duplicates in the data.
Data drift, or distribution shift, refers to changes in the underlying statistical properties of the input data to an operational AI system. Over time, the input data can become significantly different from the data originally used to train the model. [7],[8] Degradation caused by data drift is a natural and expected occurrence, and AI system developers and operators need to regularly update models to maintain accuracy and performance. Data drift ordinarily begins as small, seemingly insignificant degradations in model performance. Left unchecked, the degradation caused by data drift can snowball into substantial reductions in AI system accuracy and integrity that become increasingly difficult to correct.
It is crucial to distinguish between data drift and data poisoning attacks designed to affect an AI model. Continuous monitoring of system accuracy and performance provides important indicators based on the nature of the changes observed. If the changes are slow and gradual over time, it is more likely that the model is experiencing data drift. If the changes are abrupt and dramatic in one or more dimensions, it is more likely that an actor is trying to compromise the model. Cyber compromises often aim to manipulate the model’s performance quickly and significantly, leading to abrupt changes in the input data or model outputs.
AI system operators and developers should employ a wide range of techniques for detecting and mitigating data drift, including data preprocessing, increasing dataset coverage of real-world scenarios, and adopting robust training and adaptation strategies. [30] Packages that automate dataset loading assist AI system developers in creating application-specific detection and mitigation techniques for data drift.
There are many potential causes of data drift, including:
A change in the upstream data pipeline not represented in the model training data (e.g., the units of a particular data element change from miles to kilometers)
The introduction of completely new data elements that the model had not previously seen (e.g., a new type of malware not recognized in the ML layer of an anti-virus product)
A change in the context of how inputs and outputs are related (e.g., a change in organizational structure due to a merger or acquisition could lead to new data access patterns that might be misinterpreted as security threats by an AI system)
The data associated with a given AI model should be regularly checked for any updates to help ensure the model still predicts as expected. [7],[8],[9] The interval for this update and check will depend on the particular AI system and application. For example, in high-stakes applications such as healthcare, early detection and mitigation of data drift are critical prior to patient impact. Thus, continuous monitoring of model performance with additional direct analysis of the input data is important in such applications. [30]
Mitigation strategies:
Data management: Employ a data management strategy in keeping with the best practices in this CSI to help ensure that it is easy to add and track new data elements for model training and adaptation. This management strategy enables identification of data elements causing drift for appropriate mitigation or action.
Data-quality testing: AI system developers should use data-quality assessment tools to assist in selecting and filtering data used for model training or adaptation. Understanding the current dataset and its impact on model behavior is critical to detecting data drift.
Input and output monitoring: Monitor the AI system inputs and outputs to verify the model is performing as expected. [9] Regularly update your model using current data. Utilize meaningful statistical methods that measure expected dataset metrics and compare the distribution of the training data to the test data to help determine if data drift is occurring. [7]
Data management tools and methods are currently an active area of research. However, data drift can be mitigated by incorporating application-specific data management protocols that include: continuous monitoring, retraining (regularly incorporating the latest data into the models), data cleansing (correcting errors or inconsistencies in the data), and using ensemble models (combining predictions of multiple models). Incorporation of a data management framework into the design of AI systems from the beginning is essential for improving the overall integrity and security posture. [31]
Conclusion
Data security is of paramount importance when developing and operating AI systems. As organizations in various sectors rely more and more on AI-driven outcomes, data security becomes crucial for maintaining accuracy, reliability, and integrity. The guidance provided in this CSI outlines a robust approach to securing AI data and addressing the risks associated with the data supply chain, malicious data, and data drift.
Data security is an ever-evolving field, and continuous vigilance and adaptation are key to staying ahead of emerging threats and vulnerabilities. The best practices presented here encourage the highest standards of data security in AI while helping ensure the accuracy and integrity of AI-driven outcomes. By adopting these best practices and risk mitigation strategies, organizations can fortify their AI systems against potential threats and safeguard sensitive, proprietary, and mission critical data used in the development and operation of their AI systems.
References
1 In this document, Artificial Intelligence (AI) has the meaning set forth in 15 U.S.C. 9401(3): “… a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations, or decisions influencing real or virtual environments. AI systems use machine- and human-based inputs to: (A) Perceive real and virtual environments; (B) Take these perceptions and turn them into models through analysis in an automated manner; and (C) Use model inference to formulate options for information or action.”
2Data integrity is defined by the IC Data Management Lexicon [1] as “The degree to which data can be trusted due to its provenance, pedigree, lineage and conformance with all business rules regarding its relationship with other data. In the context of data movement, this is the degree to which data has verifiably not been changed unexpectedly by a person or NPE.”
3The term data consumers is defined as technical personnel (e.g. data scientists, engineers) who make use of data that they themselves did not produce or annotate to build and/or operate AI systems.
4Model inversion refers to the process by which an attacker analyzes the output patterns of an AI system to reverse-engineer and uncover details about the training dataset, such as individual data points or patterns. This process can potentially expose confidential or proprietary information from the data that was used to train the AI models.
5“A data statement is a characterization of a dataset that provides context to allow developers and users to better understand how experimental results might generalize, how software might be appropriately deployed, and what biases might be reflected in systems built on the software.” [23]
6“In technical systems, bias is most commonly understood and treated as a statistical phenomenon. Bias is an effect that deprives a statistical result of representativeness by systematically distorting it, as distinct from random error, which may distort on any one occasion but balances out on the average.” [26],[32]
The information and opinions contained in this document are provided “as is” and without any warranties or guarantees. Reference herein to any specific commercial products, process, or service by trade name, trademark, manufacturer, or otherwise, does not constitute or imply its endorsement, recommendation, or favoring by the United States Government, and this guidance shall not be used for advertising or product endorsement purposes.
Purpose
This document was developed in furtherance of the authoring organizations’ cybersecurity missions, including their responsibilities to identify and disseminate threats, and to develop and issue cybersecurity specifications and mitigations. This information may be shared broadly to reach all appropriate stakeholders.
Notice of Generative AI Use
Generative AI technology was carefully and responsibly used in the development of this document. The authors maintain ultimate responsibility for the accuracy of the information provided herein.
Today, CISA and the Federal Bureau of Investigation released a joint Cybersecurity Advisory, LummaC2 Malware Targeting U.S. Critical Infrastructure Sectors.
This advisory details the tactics, techniques, and procedures, and indicators of compromise (IOCs) linked to threat actors deploying LummaC2 malware. This malware poses a serious threat, capable of infiltrating networks and exfiltrating sensitive information, to vulnerable individuals’ and organizations’ computer networks across U.S. critical infrastructure sectors.
As recently as May 2025, threat actors have been observed using LummaC2 malware, underscoring the ongoing threat. The advisory includes IOCs tied to infections from November 2023 through May 2025. Organizations are strongly urged to review the advisory and implement the recommended mitigations to reduce exposure and impact.
This advisory details the tactics, techniques, and procedures, and indicators of compromise (IOCs) linked to threat actors deploying LummaC2 malware. This malware poses a serious threat, capable of infiltrating networks and exfiltrating sensitive information, to vulnerable individuals’ and organizations’ computer networks across U.S. critical infrastructure sectors.
As recently as May 2025, threat actors have been observed using LummaC2 malware, underscoring the ongoing threat. The advisory includes IOCs tied to infections from November 2023 through May 2025. Organizations are strongly urged to review the advisory and implement the recommended mitigations to reduce exposure and impact.
2. RISK EVALUATION
Successful exploitation of this vulnerability could enable a remote attacker to bypass authentication and execute arbitrary code remotely.
3. TECHNICAL DETAILS
3.1 AFFECTED PRODUCTS
The following versions of AK-SM 800A system manager are affected:
AK-SM 8xxA Series: Versions prior to R4.2
3.2 VULNERABILITY OVERVIEW
3.2.1 IMPROPER AUTHENTICATION CWE-287
An unauthorized access vulnerability, caused by datetime-based password generation, could potentially result in an authentication bypass.
CVE-2025-41450 has been assigned to this vulnerability. A CVSS v3.1 base score of 8.2 has been calculated; the CVSS vector string is (CVSS:3.1/AV:N/AC:H/PR:N/UI:R/S:C/C:H/I:L/A:H).
A CVSS v4 score has also been calculated for CVE-2025-41450. A base score of 7.3 has been calculated; the CVSS vector string is (CVSS:4.0/AV:N/AC:H/AT:N/PR:N/UI:P/VC:H/VI:L/VA:H/SC:H/SI:L/SA:H).
3.3 BACKGROUND
3.4 RESEARCHER
Tomer Goldschmidt of Claroty Team82 reported this vulnerability to CISA.
4. MITIGATIONS
Danfoss has created release R4.2 to address this vulnerability. Users can obtain and install the latest version by following the AK-SM 800A Software Upgrade Process.
For more information, please see the Danfoss security advisory.
CISA recommends users take defensive measures to minimize the risk of exploitation of this vulnerability, such as:
Minimize network exposure for all control system devices and/or systems, ensuring they are not accessible from the Internet.
Locate control system networks and remote devices behind firewalls and isolating them from business networks.
When remote access is required, use more secure methods, such as virtual private networks (VPNs), recognizing VPNs may have vulnerabilities and should be updated to the most current version available. Also recognize VPN is only as secure as the connected devices.
CISA reminds organizations to perform proper impact analysis and risk assessment prior to deploying defensive measures.
CISA also provides a section for control systems security recommended practices on the ICS webpage on cisa.gov/ics. Several CISA products detailing cyber defense best practices are available for reading and download, including Improving Industrial Control Systems Cybersecurity with Defense-in-Depth Strategies.
CISA encourages organizations to implement recommended cybersecurity strategies for proactive defense of ICS assets.
Additional mitigation guidance and recommended practices are publicly available on the ICS webpage at cisa.gov/ics in the technical information paper, ICS-TIP-12-146-01B–Targeted Cyber Intrusion Detection and Mitigation Strategies.
Organizations observing suspected malicious activity should follow established internal procedures and report findings to CISA for tracking and correlation against other incidents.
CISA also recommends users take the following measures to protect themselves from social engineering attacks:
Do not click web links or open attachments in unsolicited email messages.
Refer to Recognizing and Avoiding Email Scams for more information on avoiding email scams.
Refer to Avoiding Social Engineering and Phishing Attacks for more information on social engineering attacks.
No known public exploitation specifically targeting this vulnerability has been reported to CISA at this time. This vulnerability has a high attack complexity.
5. UPDATE HISTORY
Locate control system networks and remote devices behind firewalls and isolating them from business networks.
When remote access is required, use more secure methods, such as virtual private networks (VPNs), recognizing VPNs may have vulnerabilities and should be updated to the most current version available. Also recognize VPN is only as secure as the connected devices.
CISA reminds organizations to perform proper impact analysis and risk assessment prior to deploying defensive measures.
Organizations observing suspected malicious activity should follow established internal procedures and report findings to CISA for tracking and correlation against other incidents.
CISA also recommends users take the following measures to protect themselves from social engineering attacks:
Do not click web links or open attachments in unsolicited email messages.
No known public exploitation specifically targeting this vulnerability has been reported to CISA at this time. This vulnerability has a high attack complexity.
CVSS v4 9.3
ATTENTION: Exploitable remotely/low attack complexity
Vendor: Vertiv
Equipment: Liebert RDU101 and Liebert UNITY
Vulnerabilities: Authentication Bypass Using an Alternate Path or Channel, Stack-based Buffer Overflow
2. RISK EVALUATION
Successful exploitation of these vulnerabilities could allow an attacker to cause a denial-of-service condition or achieve remote code execution
3. TECHNICAL DETAILS
3.1 AFFECTED PRODUCTS
The following Vertiv products are affected:
Liebert RDU101: Versions 1.9.0.0 and prior
Liebert IS-UNITY: Versions 8.4.1.0 and prior
3.2 VULNERABILITY OVERVIEW
3.2.1 AUTHENTICATION BYPASS USING AN ALTERNATE PATH OR CHANNEL CWE-288
Affected Vertiv products do not properly protect webserver functions that could allow an attacker to bypass authentication.
CVE-2025-46412 has been assigned to this vulnerability. A CVSS v3.1 base score of 9.8 has been calculated; the CVSS vector string is (AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H).
A CVSS v4 score has also been calculated for CVE-2025-46412. A base score of 9.3 has been calculated; the CVSS vector string is (AV:N/AC:L/AT:N/PR:N/UI:N/VC:H/VI:H/VA:H/SC:N/SI:N/SA:N).
3.2.2 STACK-BASED BUFFER OVERFLOW CWE-121
Affected Vertiv products contain a stack based buffer overflow vulnerability. An attacker could exploit this vulnerability to gain code execution on the device.
CVE-2025-41426 has been assigned to this vulnerability. A CVSS v3.1 base score of 9.8 has been calculated; the CVSS vector string is (AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H).
A CVSS v4 score has also been calculated for CVE-2025-41426. A base score of 9.3 has been calculated; the CVSS vector string is (AV:N/AC:L/AT:N/PR:N/UI:N/VC:H/VI:H/VA:H/SC:N/SI:N/SA:N).
3.3 BACKGROUND
CRITICAL INFRASTRUCTURE SECTORS: Communications, Energy
COUNTRIES/AREAS DEPLOYED: Worldwide
COMPANY HEADQUARTERS LOCATION: United States
3.4 RESEARCHER
Vera Mens of Claroty Team82 reported this these vulnerabilities to CISA.
4. MITIGATIONS
Vertiv recommends users take the following actions:
Update Liebert RDU101 to v1.9.1.2_0000001
Update IS-UNITY to v8.4.3.1_00160
For more information please contact Vertiv.
CISA recommends users take defensive measures to minimize the risk of exploitation of these vulnerabilities, such as:
Minimize network exposure for all control system devices and/or systems, ensuring they are not accessible from the internet.
Locate control system networks and remote devices behind firewalls and isolating them from business networks.
When remote access is required, use more secure methods, such as Virtual Private Networks (VPNs), recognizing VPNs may have vulnerabilities and should be updated to the most current version available. Also recognize VPN is only as secure as the connected devices.
CISA reminds organizations to perform proper impact analysis and risk assessment prior to deploying defensive measures.
CISA also provides a section for control systems security recommended practices on the ICS webpage on cisa.gov/ics. Several CISA products detailing cyber defense best practices are available for reading and download, including Improving Industrial Control Systems Cybersecurity with Defense-in-Depth Strategies.
CISA encourages organizations to implement recommended cybersecurity strategies for proactive defense of ICS assets.
Additional mitigation guidance and recommended practices are publicly available on the ICS webpage at cisa.gov/ics in the technical information paper, ICS-TIP-12-146-01B–Targeted Cyber Intrusion Detection and Mitigation Strategies.
Organizations observing suspected malicious activity should follow established internal procedures and report findings to CISA for tracking and correlation against other incidents.
No known public exploitation specifically targeting these vulnerabilities has been reported to CISA at this time.
5. UPDATE HISTORY
Affected Vertiv products contain a stack based buffer overflow vulnerability. An attacker could exploit this vulnerability to gain code execution on the device.
Locate control system networks and remote devices behind firewalls and isolating them from business networks.
When remote access is required, use more secure methods, such as Virtual Private Networks (VPNs), recognizing VPNs may have vulnerabilities and should be updated to the most current version available. Also recognize VPN is only as secure as the connected devices.
CISA reminds organizations to perform proper impact analysis and risk assessment prior to deploying defensive measures.
Organizations observing suspected malicious activity should follow established internal procedures and report findings to CISA for tracking and correlation against other incidents.
No known public exploitation specifically targeting these vulnerabilities has been reported to CISA at this time.
Summary
The Federal Bureau of Investigation (FBI) and the Cybersecurity and Infrastructure Security Agency (CISA) are releasing this joint advisory to disseminate known tactics, techniques, and procedures (TTPs) and indicators of compromise (IOCs) associated with threat actors deploying the LummaC2 information stealer (infostealer) malware. LummaC2 malware is able to infiltrate victim computer networks and exfiltrate sensitive information, threatening vulnerable individuals’ and organizations’ computer networks across multiple U.S. critical infrastructure sectors. According to FBI information and trusted third-party reporting, this activity has been observed as recently as May 2025. The IOCs included in this advisory were associated with LummaC2 malware infections from November 2023 through May 2025.
The FBI and CISA encourage organizations to implement the recommendations in the Mitigations section of this advisory to reduce the likelihood and impact of LummaC2 malware.
Download the PDF version of this report:
AA25-141B Threat Actors Deploy LummaC2 Malware to Exfiltrate Sensitive Data from Organizations
(PDF, 1.28 MB
)
For a downloadable copy of IOCs, see:
AA25-141B STIX XML
(XML, 146.54 KB
)
AA25-141B STIX JSON
(JSON, 300.90 KB
)
Technical Details
Note: This advisory uses the MITRE ATT&CK® Matrix for Enterprise framework, version 17. See the MITRE ATT&CK Tactics and Techniques section of this advisory for threat actor activity mapped to MITRE ATT&CK tactics and techniques.
Overview
LummaC2 malware first appeared for sale on multiple Russian-language speaking cybercriminal forums in 2022. Threat actors frequently use spearphishing hyperlinks and attachments to deploy LummaC2 malware payloads [T1566.001, T1566.002]. Additionally, threat actors rely on unsuspecting users to execute the payload by clicking a fake Completely Automated Public Turing Test to tell Computers and Humans Apart (CAPTCHA). The CAPTCHA contains instructions for users to then open the Windows Run window (Windows Button + R) and paste clipboard contents (“CTRL + V”). After users press “enter” a subsequent Base64-encoded PowerShell process is executed.
To obfuscate their operations, threat actors have embedded and distributed LummaC2 malware within spoofed or fake popular software (i.e., multimedia player or utility software) [T1036]. The malware’s obfuscation methods allow LummaC2 actors to bypass standard cybersecurity measures, such as Endpoint Detection and Response (EDR) solutions or antivirus programs, designed to flag common phishing attempts or drive-by downloads [T1027].
Once a victim’s computer system is infected, the malware can exfiltrate sensitive user information, including personally identifiable information, financial credentials, cryptocurrency wallets, browser extensions, and multifactor authentication (MFA) details without immediate detection [TA0010, T1119]. Private sector statistics indicate there were more than 21,000 market listings selling LummaC2 logs on multiple cybercriminal forums from April through June of 2024, a 71.7 percent increase from April through June of 2023.
File Execution
Upon execution, the LummaC2.exe file will enter its main routine, which includes four sub-routines (see Figure 1).
Figure 1. LummaC2 Main Routine
The first routine decrypts strings for a message box that is displayed to the user (see Figure 2).
Figure 2. Message Box
If the user selects No, the malware will exit. If the user selects Yes, the malware will move on to its next routine, which decrypts its callback Command and Control (C2) domains [T1140]. A list of observed domains is included in the Indicators of Compromise section.
After each domain is decoded, the implant will attempt a POST request [T1071.001] (see Figure 3).
Figure 3. Post Request
If the POST request is successful, a pointer to the decoded domain string is saved in a global variable for later use in the main C2 routine used to retrieve JSON formatted commands (see Figure 4).
Figure 4. Code Saving Successful Callback Request
Once a valid C2 domain is contacted and saved, the malware moves on to the next routine, which queries the user’s name and computer name utilizing the Application Programming Interfaces (APIs) GetUserNameW and GetComputerNameW respectively [T1012]. The returned data is then hashed and compared against a hard-coded hash value (see Figure 5).
Figure 5. User and Computer Name Check
The hashing routine was not identified as a standard algorithm; however, it is a simple routine that converts a Unicode string to a 32-bit hexadecimal value.
If the username hash is equal to the value 0x56CF7626, then the computer name is queried. If the computer name queried is seven characters long, then the name is hashed and checked against the hard-coded value of 0xB09406C7. If both values match, a final subroutine will be called with a static value of the computer name hash as an argument. If this routine is reached, the process will terminate. This is most likely a failsafe to prevent the malware from running on the attacker’s system, as its algorithms are one-way only and will not reveal information on the details of the attacker’s own hostname and username.
If the username and hostname check function returns zero (does not match the hard-coded values), the malware will enter its main callback routine. The LummaC2 malware will contact the saved hostname from the previous check and send the following POST request (see Figure 6).
Figure 6. Second POST Request
The data returned from the C2 server is encrypted. Once decoded, the C2 data is in a JSON format and is parsed by the LummaC2 malware. The C2 uses the JSON configuration to parse its browser extensions and target lists using the ex key, which contains an array of objects (see Figure 7).
Figure 7. Parsing of ex JSON Value
Parsing the c key contains an array of objects, which will give the implant its C2 (see Figure 8).
Figure 8. Parsing of c JSON Value
C2 Instructions
Each array object that contains the JSON key value of t will be evaluated as a command opcode, resulting in the C2 instructions in the subsections below.
1. Opcode 0 – Steal Data Generic
This command allows five fields to be defined when stealing data, offering the most flexibility. The Opcode O command option allows LummaC2 affiliates to add their custom information gathering details (see Table 1).
Table 2. Opcode 1 Options
Key
Value
p
Path to steal from
m
File extensions to read
z
Output directory to store stolen data
d
Depth of recursiveness
fs
Maximum file size
2. Opcode 1 – Steal Browser Data
This command only allows for two options: a path and the name of the output directory. This command, based on sample configuration downloads, is used for browser data theft for everything except Mozilla [T1217] (see Table 2).
Table 2. Opcode 1 Options
Key
Value
p
Path to steal from
z
Name of Browser – Output
3. Opcode 2 – Steal Browser Data (Mozilla)
This command is identical to Opcode 1; however, this option seems to be utilized solely for Mozilla browser data (see Table 3).
Table 3. Opcode 2 Options
Key
Value
p
Path to steal from
z
Name of Browser – Output
4. Opcode 3 – Download a File
This command contains three options: a URL, file extension, and execution type. The configuration can specify a remote file with u to download and create the extension specified in the ft key [T1105] (see Table 4).
Table 4. Opcode 3 Options
Key
Value
u
URL for Download
ft
File Extension
e
Execution Type
The e value can take two values: 0 or 1. This specifies how to execute the downloaded file either with the LoadLibrary API or via the command line with rundll32.exe [T1106] (see Table 5).
Table 5. Execution Types
Key
Value
e=0
Execute with LoadLibraryW()
e=1
Executive with rund1132.exe
5. Take Screenshot
If the configuration JSON file has a key of “se” and its value is “true,” the malware will take a screenshot in BMP format and upload it to the C2 server.
6. Delete Self
If the configuration JSON file has a key of “ad” and its value is “true,” the malware will enter a routine to delete itself.
The command shown in Figure 9 will be decoded and executed for self-deletion.
Figure 9. Self-Deletion Command Line
Figure 10 depicts the above command line during execution.
Figure 10. Decoded Command Line in Memory
Host Modifications
Without any C2 interactions, the LummaC2 malware does not create any files on the infected drive. It simply runs in memory, gathers system information, and exfiltrates it to the C2 server [T1082]. The commands returned from the C2 server could indicate that it drops additional files and/or saves data to files on the local hard drive. This is variable, as these commands come from the C2 server and are mutable.
Decrypted Strings
Below is a list of hard-coded decrypted strings located in the binary (see Figure 11).
Figure 11. Decoded Strings
Indicators of Compromise
See Table 6 and Table 7 for LummaC2 IOCs obtained by the FBI and trusted third parties.
Disclaimer: The authoring agencies recommend organizations investigate and vet these indicators of compromise prior to taking action, such as blocking.
Table 6. LummaC2 Executable Hashes
Executables
Type
4AFDC05708B8B39C82E60ABE3ACE55DB (LummaC2.exe from November 2023)
MD5
E05DF8EE759E2C955ACC8D8A47A08F42 (LummaC2.exe from November 2023)
MD5
C7610AE28655D6C1BCE88B5D09624FEF
MD5
1239288A5876C09D9F0A67BCFD645735168A7C80 (LummaC2.exe from November 2023)
SHA1
B66DA4280C6D72ADCC68330F6BD793DF56A853CB (LummaC2.exe from November 2023)
SHA1
MITRE ATT&CK Tactics and Techniques
See Table 8 through Table 13 for all referenced threat actor tactics and techniques in this advisory. For assistance with mapping malicious cyber activity to the MITRE ATT&CK framework, see CISA and MITRE ATT&CK’s Best Practices for MITRE ATT&CK Mapping and CISA’s Decider Tool.
Table 8. Initial Access
Technique Title
ID
Use
Phishing
T1566
Threat actors delivered LummaC2 malware through phishing emails.
Phishing: Spearphishing Attachment
T1566.001
Threat actors used spearphishing attachments to deploy LummaC2 malware payloads.
Phishing: Spearphishing Link
T1566.002
Threat actors used spearphishing hyperlinks to deploy LummaC2 malware payloads.
Table 9. Defense Evasion
Technique Title
ID
Use
Obfuscated Files or Information
T1027
Threat actors obfuscated the malware to bypass standard cybersecurity measures designed to flag common phishing attempts or drive-by downloads.
Masquerading
T1036
Threat actors delivered LummaC2 malware via spoofed software.
Deobfuscate/Decode Files or Information
T1140
Threat actors used LummaC2 malware to decrypt its callback C2 domains.
Table 10. Discovery
Technique Title
ID
Use
Query Registry
T1012
Threat actors used LummaC2 malware to query the user’s name and computer name utilizing the APIs GetUserNameW and GetComputerNameW.
Browser Information Discovery
T1217
Threat actors used LummaC2 malware to steal browser data.
Table 11. Collection
Technique Title
ID
Use
Automated Collection
T1119
LummaC2 malware has automated collection of various information including cryptocurrency wallet details.
Table 12. Command and Control
Technique Title
ID
Use
Application Layer Protocol: Web Protocols
T1071.001
Threat actors used LummaC2 malware to attempt POST requests.
Ingress Tool Transfer
T1105
Threat actors used LummaC2 malware to transfer a remote file to compromised systems.
Table 13. Exfiltration
Technique Title
ID
Use
Exfiltration
TA0010
Threat actors used LummaC2 malware to exfiltrate sensitive user information, including traditional credentials, cryptocurrency wallets, browser extensions, and MFA details without immediate detection.
Native API
T1106
Threat actors used LummaC2 malware to download files with native OS APIs.
Mitigations
The FBI and CISA recommend organizations implement the mitigations below to reduce the risk of compromise by LummaC2 malware. These mitigations align with the Cross-Sector Cybersecurity Performance Goals (CPGs) developed by CISA and the National Institute of Standards and Technology (NIST). The CPGs provide a minimum set of practices and protections that CISA and NIST recommend all organizations implement. CISA and NIST based the CPGs on existing cybersecurity frameworks and guidance to protect against the most common and impactful threats, tactics, techniques, and procedures. Visit CISA’s CPGs webpage for more information on the CPGs, including additional recommended baseline protections. These mitigations apply to all critical infrastructure organizations.
Separate User and Privileged Accounts: Allow only necessary users and applications access to the registry [CPG 2.E].
Monitor and detect suspicious behavior during exploitation [CPG 3.A].
Monitor and detect suspicious behavior, creation and termination events, and unusual and unexpected processes running.
Monitor API calls that may attempt to retrieve system information.
Analyze behavior patterns from process activities to identify anomalies.
For more information, visit CISA’s guidance on: Enhanced Visibility and Hardening Guidance for Communications Infrastructure.
Implement application controls to manage and control execution of software, including allowlisting remote access programs. Application controls should prevent installation and execution of portable versions of unauthorized remote access and other software. A properly configured application allowlisting solution will block any unlisted application execution. Allowlisting is important because antivirus solutions may fail to detect the execution of malicious portable executables when the files use any combination of compression, encryption, or obfuscation.
Protect against threat actor phishing campaigns by implementing CISA’s Phishing Guidance and Phishing-resistant multifactor authentication. [CPG 2.H]
Log Collection: Regularly monitoring and reviewing registry changes and access logs can support detection of LummaC2 malware [CPG 2.T].
Implement authentication, authorization, and accounting (AAA) systems [M1018] to limit actions users can perform and review logs of user actions to detect unauthorized use and abuse. Apply principles of least privilege to user accounts and groups, allowing only the performance of authorized actions.
Audit user accounts and revoke credentials for departing employees, removing those that are inactive or unnecessary on a routine basis [CPG 2.D]. Limit the ability for user accounts to create additional accounts.
Keep systems up to date with regular updates, patches, hot fixes, and service packs that may minimize vulnerabilities. Learn more by visiting CISA’s webpage: Secure our World Update Software.
Secure network devices to restrict command line access.
Learn more about defending against the malicious use of remote access software by visiting CISA’s Guide to Securing Remote Access Software.
Use segmentation to prevent access to sensitive systems and information, possibly with the use of Demilitarized Zone (DMZ) or virtual private cloud (VPC) instances to isolate systems [CPG 2.F].
Monitor and detect API usage, looking for unusual or malicious behavior.
Validate Security Controls
In addition to applying mitigations, the FBI and CISA recommend exercising, testing, and validating your organization’s security program against threat behaviors mapped to the MITRE ATT&CK Matrix for Enterprise framework in this advisory. The FBI and CISA recommend testing your existing security controls inventory to assess performance against the ATT&CK techniques described in this advisory.
To get started:
Select an ATT&CK technique described in this advisory (see Table 8 through Table 13).
Align your security technologies against the technique.
Test your technologies against the technique.
Analyze your detection and prevention technologies’ performance.
Repeat the process for all security technologies to obtain a set of comprehensive performance data.
Tune your security program, including people, processes, and technologies, based on the data generated by this process.
The FBI and CISA recommend continually testing your security program, at scale, in a production environment to ensure optimal performance against the MITRE ATT&CK techniques identified in this advisory.
Reporting
Your organization has no obligation to respond or provide information to the FBI in response to this joint advisory. If, after reviewing the information provided, your organization decides to provide information to the FBI, reporting must be consistent with applicable state and federal laws.
The FBI is interested in any information that can be shared, to include the status and scope of infection, estimated loss, date of infection, date detected, initial attack vector, and host- and network-based indicators.
To report information, please contact the FBI’s Internet Crime Complaint Center (IC3), your local FBI field office, or CISA’s 24/7 Operations Center at report@cisa.gov or (888) 282-0870.
Disclaimer
The information in this report is being provided “as is” for informational purposes only. The FBI and CISA do not endorse any commercial entity, product, company, or service, including any entities, products, or services linked within this document. Any reference to specific commercial entities, products, processes, or services by service mark, trademark, manufacturer, or otherwise, does not constitute or imply endorsement, recommendation, or favor by the FBI and CISA.
Acknowledgements
ReliaQuest contributed to this advisory.
Version History
May 21, 2025: Initial version.
Summary
The Federal Bureau of Investigation (FBI) and the Cybersecurity and Infrastructure Security Agency (CISA) are releasing this joint advisory to disseminate known tactics, techniques, and procedures (TTPs) and indicators of compromise (IOCs) associated with threat actors deploying the LummaC2 information stealer (infostealer) malware. LummaC2 malware is able to infiltrate victim computer networks and exfiltrate sensitive information, threatening vulnerable individuals’ and organizations’ computer networks across multiple U.S. critical infrastructure sectors. According to FBI information and trusted third-party reporting, this activity has been observed as recently as May 2025. The IOCs included in this advisory were associated with LummaC2 malware infections from November 2023 through May 2025.
The FBI and CISA encourage organizations to implement the recommendations in the Mitigations section of this advisory to reduce the likelihood and impact of LummaC2 malware.
Note: This advisory uses the MITRE ATT&CK® Matrix for Enterprise framework, version 17. See the MITRE ATT&CK Tactics and Techniques section of this advisory for threat actor activity mapped to MITRE ATT&CK tactics and techniques.
Overview
LummaC2 malware first appeared for sale on multiple Russian-language speaking cybercriminal forums in 2022. Threat actors frequently use spearphishing hyperlinks and attachments to deploy LummaC2 malware payloads [T1566.001, T1566.002]. Additionally, threat actors rely on unsuspecting users to execute the payload by clicking a fake Completely Automated Public Turing Test to tell Computers and Humans Apart (CAPTCHA). The CAPTCHA contains instructions for users to then open the Windows Run window (Windows Button + R) and paste clipboard contents (“CTRL + V”). After users press “enter” a subsequent Base64-encoded PowerShell process is executed.
To obfuscate their operations, threat actors have embedded and distributed LummaC2 malware within spoofed or fake popular software (i.e., multimedia player or utility software) [T1036]. The malware’s obfuscation methods allow LummaC2 actors to bypass standard cybersecurity measures, such as Endpoint Detection and Response (EDR) solutions or antivirus programs, designed to flag common phishing attempts or drive-by downloads [T1027].
Once a victim’s computer system is infected, the malware can exfiltrate sensitive user information, including personally identifiable information, financial credentials, cryptocurrency wallets, browser extensions, and multifactor authentication (MFA) details without immediate detection [TA0010, T1119]. Private sector statistics indicate there were more than 21,000 market listings selling LummaC2 logs on multiple cybercriminal forums from April through June of 2024, a 71.7 percent increase from April through June of 2023.
File Execution
Upon execution, the LummaC2.exe file will enter its main routine, which includes four sub-routines (see Figure 1).
Figure 1. LummaC2 Main Routine
The first routine decrypts strings for a message box that is displayed to the user (see Figure 2).
Figure 2. Message Box
If the user selects No, the malware will exit. If the user selects Yes, the malware will move on to its next routine, which decrypts its callback Command and Control (C2) domains [T1140]. A list of observed domains is included in the Indicators of Compromise section.
After each domain is decoded, the implant will attempt a POST request [T1071.001] (see Figure 3).
Figure 3. Post Request
If the POST request is successful, a pointer to the decoded domain string is saved in a global variable for later use in the main C2 routine used to retrieve JSON formatted commands (see Figure 4).
Figure 4. Code Saving Successful Callback Request
Once a valid C2 domain is contacted and saved, the malware moves on to the next routine, which queries the user’s name and computer name utilizing the Application Programming Interfaces (APIs) GetUserNameW and GetComputerNameW respectively [T1012]. The returned data is then hashed and compared against a hard-coded hash value (see Figure 5).
Figure 5. User and Computer Name Check
The hashing routine was not identified as a standard algorithm; however, it is a simple routine that converts a Unicode string to a 32-bit hexadecimal value.
If the username hash is equal to the value 0x56CF7626, then the computer name is queried. If the computer name queried is seven characters long, then the name is hashed and checked against the hard-coded value of 0xB09406C7. If both values match, a final subroutine will be called with a static value of the computer name hash as an argument. If this routine is reached, the process will terminate. This is most likely a failsafe to prevent the malware from running on the attacker’s system, as its algorithms are one-way only and will not reveal information on the details of the attacker’s own hostname and username.
If the username and hostname check function returns zero (does not match the hard-coded values), the malware will enter its main callback routine. The LummaC2 malware will contact the saved hostname from the previous check and send the following POST request (see Figure 6).
Figure 6. Second POST Request
The data returned from the C2 server is encrypted. Once decoded, the C2 data is in a JSON format and is parsed by the LummaC2 malware. The C2 uses the JSON configuration to parse its browser extensions and target lists using the ex key, which contains an array of objects (see Figure 7).
Figure 7. Parsing of ex JSON Value
Parsing the c key contains an array of objects, which will give the implant its C2 (see Figure 8).
Figure 8. Parsing of c JSON Value
C2 Instructions
Each array object that contains the JSON key value of t will be evaluated as a command opcode, resulting in the C2 instructions in the subsections below.
1. Opcode 0 – Steal Data Generic
This command allows five fields to be defined when stealing data, offering the most flexibility. The Opcode O command option allows LummaC2 affiliates to add their custom information gathering details (see Table 1).
Table 2. Opcode 1 Options
Key
Value
p
Path to steal from
m
File extensions to read
z
Output directory to store stolen data
d
Depth of recursiveness
fs
Maximum file size
2. Opcode 1 – Steal Browser Data
This command only allows for two options: a path and the name of the output directory. This command, based on sample configuration downloads, is used for browser data theft for everything except Mozilla [T1217] (see Table 2).
Table 2. Opcode 1 Options
Key
Value
p
Path to steal from
z
Name of Browser – Output
3. Opcode 2 – Steal Browser Data (Mozilla)
This command is identical to Opcode 1; however, this option seems to be utilized solely for Mozilla browser data (see Table 3).
Table 3. Opcode 2 Options
Key
Value
p
Path to steal from
z
Name of Browser – Output
4. Opcode 3 – Download a File
This command contains three options: a URL, file extension, and execution type. The configuration can specify a remote file with u to download and create the extension specified in the ft key [T1105] (see Table 4).
Table 4. Opcode 3 Options
Key
Value
u
URL for Download
ft
File Extension
e
Execution Type
The e value can take two values: 0 or 1. This specifies how to execute the downloaded file either with the LoadLibrary API or via the command line with rundll32.exe [T1106] (see Table 5).
Table 5. Execution Types
Key
Value
e=0
Execute with LoadLibraryW()
e=1
Executive with rund1132.exe
5. Take Screenshot
If the configuration JSON file has a key of “se” and its value is “true,” the malware will take a screenshot in BMP format and upload it to the C2 server.
6. Delete Self
If the configuration JSON file has a key of “ad” and its value is “true,” the malware will enter a routine to delete itself.
The command shown in Figure 9 will be decoded and executed for self-deletion.
Figure 9. Self-Deletion Command Line
Figure 10 depicts the above command line during execution.
Figure 10. Decoded Command Line in Memory
Host Modifications
Without any C2 interactions, the LummaC2 malware does not create any files on the infected drive. It simply runs in memory, gathers system information, and exfiltrates it to the C2 server [T1082]. The commands returned from the C2 server could indicate that it drops additional files and/or saves data to files on the local hard drive. This is variable, as these commands come from the C2 server and are mutable.
Decrypted Strings
Below is a list of hard-coded decrypted strings located in the binary (see Figure 11).
Figure 11. Decoded Strings
Indicators of Compromise
See Table 6 and Table 7 for LummaC2 IOCs obtained by the FBI and trusted third parties.
Disclaimer: The authoring agencies recommend organizations investigate and vet these indicators of compromise prior to taking action, such as blocking.
Table 6. LummaC2 Executable Hashes
Executables
Type
4AFDC05708B8B39C82E60ABE3ACE55DB (LummaC2.exe from November 2023)
MD5
E05DF8EE759E2C955ACC8D8A47A08F42 (LummaC2.exe from November 2023)
MD5
C7610AE28655D6C1BCE88B5D09624FEF
MD5
1239288A5876C09D9F0A67BCFD645735168A7C80 (LummaC2.exe from November 2023)
SHA1
B66DA4280C6D72ADCC68330F6BD793DF56A853CB (LummaC2.exe from November 2023)
The following are domains observed deploying LummaC2 malware.
Disclaimer: The domains below are historical in nature and may not currently be malicious.
Pinkipinevazzey[.]pw
Fragnantbui[.]shop
Medicinebuckerrysa[.]pw
Musicallyageop[.]pw
stogeneratmns[.]shop
wallkedsleeoi[.]shop
Tirechinecarpet[.]pw
reinforcenh[.]shop
reliabledmwqj[.]shop
Musclefarelongea[.]pw
Forbidstow[.]site
gutterydhowi[.]shop
Fanlumpactiras[.]pw
Computeryrati[.]site
Contemteny[.]site
Ownerbuffersuperw[.]pw
Seallysl[.]site
Dilemmadu[.]site
Freckletropsao[.]pw
Opposezmny[.]site
Faulteyotk[.]site
Hemispheredodnkkl[.]pw
Goalyfeastz[.]site
Authorizev[.]site
ghostreedmnu[.]shop
Servicedny[.]site
blast-hubs[.]com
offensivedzvju[.]shop
friendseforever[.]help
blastikcn[.]com
vozmeatillu[.]shop
shiningrstars[.]help
penetratebatt[.]pw
drawzhotdog[.]shop
mercharena[.]biz
pasteflawwed[.]world
generalmills[.]pro
citywand[.]live
hoyoverse[.]blog
nestlecompany[.]pro
esccapewz[.]run
dsfljsdfjewf[.]info
naturewsounds[.]help
travewlio[.]shop
decreaserid[.]world
stormlegue[.]com
touvrlane[.]bet
governoagoal[.]pw
paleboreei[.]biz
calmingtefxtures[.]run
foresctwhispers[.]top
tracnquilforest[.]life
sighbtseeing[.]shop
advennture[.]top
collapimga[.]fun
holidamyup[.]today
pepperiop[.]digital
seizedsentec[.]online
triplooqp[.]world
easyfwdr[.]digital
strawpeasaen[.]fun
xayfarer[.]live
jrxsafer[.]top
quietswtreams[.]life
oreheatq[.]live
plantainklj[.]run
starrynsightsky[.]icu
castmaxw[.]run
puerrogfh[.]live
earthsymphzony[.]today
weldorae[.]digital
quavabvc[.]top
citydisco[.]bet
steelixr[.]live
furthert[.]run
featureccus[.]shop
smeltingt[.]run
targett[.]top
mrodularmall[.]top
ferromny[.]digital
ywmedici[.]top
jowinjoinery[.]icu
rodformi[.]run
legenassedk[.]top
htardwarehu[.]icu
metalsyo[.]digital
ironloxp[.]live
cjlaspcorne[.]icu
navstarx[.]shop
bugildbett[.]top
latchclan[.]shop
spacedbv[.]world
starcloc[.]bet
rambutanvcx[.]run
galxnetb[.]today
pomelohgj[.]top
scenarisacri[.]top
jawdedmirror[.]run
changeaie[.]top
lonfgshadow[.]live
liftally[.]top
nighetwhisper[.]top
salaccgfa[.]top
zestmodp[.]top
owlflright[.]digital
clarmodq[.]top
piratetwrath[.]run
hemispherexz[.]top
quilltayle[.]live
equatorf[.]run
latitudert[.]live
longitudde[.]digital
climatologfy[.]top
starofliught[.]top
MITRE ATT&CK Tactics and Techniques
See Table 8 through Table 13 for all referenced threat actor tactics and techniques in this advisory. For assistance with mapping malicious cyber activity to the MITRE ATT&CK framework, see CISA and MITRE ATT&CK’s Best Practices for MITRE ATT&CK Mapping and CISA’s Decider Tool.
Threat actors used LummaC2 malware to exfiltrate sensitive user information, including traditional credentials, cryptocurrency wallets, browser extensions, and MFA details without immediate detection.
Threat actors used LummaC2 malware to download files with native OS APIs.
Mitigations
The FBI and CISA recommend organizations implement the mitigations below to reduce the risk of compromise by LummaC2 malware. These mitigations align with the Cross-Sector Cybersecurity Performance Goals (CPGs) developed by CISA and the National Institute of Standards and Technology (NIST). The CPGs provide a minimum set of practices and protections that CISA and NIST recommend all organizations implement. CISA and NIST based the CPGs on existing cybersecurity frameworks and guidance to protect against the most common and impactful threats, tactics, techniques, and procedures. Visit CISA’s CPGs webpage for more information on the CPGs, including additional recommended baseline protections. These mitigations apply to all critical infrastructure organizations.
Separate User and Privileged Accounts: Allow only necessary users and applications access to the registry [CPG 2.E].
Monitor and detect suspicious behavior during exploitation [CPG 3.A].
Monitor and detect suspicious behavior, creation and termination events, and unusual and unexpected processes running.
Monitor API calls that may attempt to retrieve system information.
Analyze behavior patterns from process activities to identify anomalies.
Implement application controls to manage and control execution of software, including allowlisting remote access programs. Application controls should prevent installation and execution of portable versions of unauthorized remote access and other software. A properly configured application allowlisting solution will block any unlisted application execution. Allowlisting is important because antivirus solutions may fail to detect the execution of malicious portable executables when the files use any combination of compression, encryption, or obfuscation.
Log Collection: Regularly monitoring and reviewing registry changes and access logs can support detection of LummaC2 malware [CPG 2.T].
Implement authentication, authorization, and accounting (AAA) systems [M1018] to limit actions users can perform and review logs of user actions to detect unauthorized use and abuse. Apply principles of least privilege to user accounts and groups, allowing only the performance of authorized actions.
Audit user accounts and revoke credentials for departing employees, removing those that are inactive or unnecessary on a routine basis [CPG 2.D]. Limit the ability for user accounts to create additional accounts.
Keep systems up to date with regular updates, patches, hot fixes, and service packs that may minimize vulnerabilities. Learn more by visiting CISA’s webpage: Secure our World Update Software.
Secure network devices to restrict command line access.
Use segmentation to prevent access to sensitive systems and information, possibly with the use of Demilitarized Zone (DMZ) or virtual private cloud (VPC) instances to isolate systems [CPG 2.F].
Monitor and detect API usage, looking for unusual or malicious behavior.
Validate Security Controls
In addition to applying mitigations, the FBI and CISA recommend exercising, testing, and validating your organization’s security program against threat behaviors mapped to the MITRE ATT&CK Matrix for Enterprise framework in this advisory. The FBI and CISA recommend testing your existing security controls inventory to assess performance against the ATT&CK techniques described in this advisory.
To get started:
Select an ATT&CK technique described in this advisory (see Table 8 through Table 13).
Align your security technologies against the technique.
Test your technologies against the technique.
Analyze your detection and prevention technologies’ performance.
Repeat the process for all security technologies to obtain a set of comprehensive performance data.
Tune your security program, including people, processes, and technologies, based on the data generated by this process.
The FBI and CISA recommend continually testing your security program, at scale, in a production environment to ensure optimal performance against the MITRE ATT&CK techniques identified in this advisory.
Reporting
Your organization has no obligation to respond or provide information to the FBI in response to this joint advisory. If, after reviewing the information provided, your organization decides to provide information to the FBI, reporting must be consistent with applicable state and federal laws.
The FBI is interested in any information that can be shared, to include the status and scope of infection, estimated loss, date of infection, date detected, initial attack vector, and host- and network-based indicators.
To report information, please contact the FBI’s Internet Crime Complaint Center (IC3), your local FBI field office, or CISA’s 24/7 Operations Center at report@cisa.gov or (888) 282-0870.
Disclaimer
The information in this report is being provided “as is” for informational purposes only. The FBI and CISA do not endorse any commercial entity, product, company, or service, including any entities, products, or services linked within this document. Any reference to specific commercial entities, products, processes, or services by service mark, trademark, manufacturer, or otherwise, does not constitute or imply endorsement, recommendation, or favor by the FBI and CISA.
Today, CISA, the National Security Agency, the Federal Bureau of Investigation, and other U.S. and international partners released a joint Cybersecurity Advisory, Russian GRU Targeting Western Logistics Entities and Technology Companies.
This advisory details a Russian state-sponsored cyber espionage-oriented campaign targeting technology companies and logistics entities, including those involved in the coordination, transport, and delivery of foreign assistance to Ukraine.
Russian General Staff Main Intelligence Directorate (GRU) 85th Main Special Service Center, military unit 26165 cyber actors are using a mix of previously disclosed tactics, techniques, and procedures (TTPs) and are likely connected to these actors’ widescale targeting of IP cameras in Ukraine and bordering NATO nations.
Executives and network defenders at logistics entities and technology companies should recognize the elevated threat of until 26165 targeting, increase monitoring and threat hunting for known TTPs and indicators of compromise, and posture network defenses with a presumption of targeting. For more information on Russian state-sponsored threat actor activity, see CISA’s Russia Cyber Threat Overview and Advisories page.
This advisory details a Russian state-sponsored cyber espionage-oriented campaign targeting technology companies and logistics entities, including those involved in the coordination, transport, and delivery of foreign assistance to Ukraine.
Russian General Staff Main Intelligence Directorate (GRU) 85th Main Special Service Center, military unit 26165 cyber actors are using a mix of previously disclosed tactics, techniques, and procedures (TTPs) and are likely connected to these actors’ widescale targeting of IP cameras in Ukraine and bordering NATO nations.
Executives and network defenders at logistics entities and technology companies should recognize the elevated threat of until 26165 targeting, increase monitoring and threat hunting for known TTPs and indicators of compromise, and posture network defenses with a presumption of targeting. For more information on Russian state-sponsored threat actor activity, see CISA’s Russia Cyber Threat Overview and Advisories page.
Executive Summary
This joint cybersecurity advisory (CSA) highlights a Russian state-sponsored cyber campaign targeting Western logistics entities and technology companies. This includes those involved in the coordination, transport, and delivery of foreign assistance to Ukraine. Since 2022, Western logistics entities and IT companies have faced an elevated risk of targeting by the Russian General Staff Main Intelligence Directorate (GRU) 85th Main Special Service Center (85th GTsSS), military unit 26165—tracked in the cybersecurity community under several names (see “Cybersecurity Industry Tracking”). The actors’ cyber espionage-oriented campaign, targeting technology companies and logistics entities, uses a mix of previously disclosed tactics, techniques, and procedures (TTPs). The authoring agencies expect similar targeting and TTP use to continue.
Executives and network defenders at logistics entities and technology companies should recognize the elevated threat of unit 26165 targeting, increase monitoring and threat hunting for known TTPs and indicators of compromise (IOCs), and posture network defenses with a presumption of targeting.
This cyber espionage-oriented campaign targeting logistics entities and technology companies uses a mix of previously disclosed TTPs and is likely connected to these actors’ wide scale targeting of IP cameras in Ukraine and bordering NATO nations.
The following authors and co-sealers are releasing this CSA:
United States National Security Agency (NSA)
United States Federal Bureau of Investigation (FBI)
United Kingdom National Cyber Security Centre (NCSC-UK)
Germany Federal Intelligence Service (BND) Bundesnachrichtendienst
Germany Federal Office for Information Security (BSI) Bundesamt für Sicherheit in der Informationstechnik
Germany Federal Office for the Protection of the Constitution (BfV) Bundesamt für Verfassungsschutz
Czech Republic Military Intelligence (VZ) Vojenské zpravodajství
Czech Republic National Cyber and Information Security Agency (NÚKIB) Národní úřad pro kybernetickou a informační bezpečnost
Czech Republic Security Information Service (BIS) Bezpečnostní informační služba
Poland Internal Security Agency (ABW) Agencja Bezpieczeństwa Wewnętrznego
Poland Military Counterintelligence Service (SKW) Służba Kontrwywiadu Wojskowego
United States Cybersecurity and Infrastructure Security Agency (CISA)
United States Department of Defense Cyber Crime Center (DC3)
United States Cyber Command (USCYBERCOM)
Australian Signals Directorate’s Australian Cyber Security Centre (ASD’s ACSC)
Canadian Centre for Cyber Security (CCCS)
Danish Defence Intelligence Service (DDIS) Forsvarets Efterretningstjeneste
Estonian Foreign Intelligence Service (EFIS) Välisluureamet
Estonian National Cyber Security Centre (NCSC-EE) Küberturvalisuse keskus
French Cybersecurity Agency (ANSSI) Agence nationale de la sécurité des systèmes d’information
Netherlands Defence Intelligence and Security Service (MIVD) Militaire Inlichtingen- en Veiligheidsdienst
Download the PDF version of this report:
Russian GRU Targeting Western Logistics Entities and Technology Companies (PDF, 1,081KB)
For a downloadable list of IOCs, visit:
AA25-141A STIX XML
(XML, 117.02 KB
)
AA25-141A STIX JSON
(JSON, 144.29 KB
)
Introduction
For over two years, the Russian GRU 85th GTsSS, military unit 26165—commonly known in the cybersecurity community as APT28, Fancy Bear, Forest Blizzard, BlueDelta, and a variety of other identifiers—has conducted this campaign using a mix of known tactics, techniques, and procedures (TTPs), including reconstituted password spraying capabilities, spearphishing, and modification of Microsoft Exchange mailbox permissions.In late February 2022, multiple Russian state-sponsored cyber actors increased the variety of cyber operations for purposes of espionage, destruction, and influence—with unit 26165 predominately involved in espionage. [1] As Russian military forces failed to meet their military objectives and Western countries provided aid to support Ukraine’s territorial defense, unit 26165 expanded its targeting of logistics entities and technology companies involved in the delivery of aid. These actors have also targeted Internet-connected cameras at Ukrainian border crossings to monitor and track aid shipments.Note: This advisory uses the MITRE ATT&CK® for Enterprise framework, version 17. See Appendix A: MITRE ATT&CK tactics and techniques for a table of the threat actors’ activity mapped to MITRE ATT&CK tactics and techniques. This advisory uses the MITRE D3FEND® framework, version 1.0.
Description of Targets
The GRU unit 26165 cyber campaign against Western logistics providers and technology companies has targeted dozens of entities, including government organizations and private/commercial entities across virtually all transportation modes: air, sea, and rail. These actors have targeted entities associated with the following verticals within NATO member states, Ukraine, and at international organizations:
Defense Industry
Transportation and Transportation Hubs (ports, airports, etc.)
Maritime
Air Traffic Management
IT Services
In the course of the targeting lifecycle, unit 26165 actors identified and conducted follow-on targeting of additional entities in the transportation sector that had business ties to the primary target, exploiting trust relationships to attempt to gain additional access [T1199].
The actors also conducted reconnaissance on at least one entity involved in the production of industrial control system (ICS) components for railway management, though a successful compromise was not confirmed [TA0043].
The countries with targeted entities include the following, as illustrated in Figure 1:
Bulgaria
Czech Republic
France
Germany
Greece
Italy
Moldova
Netherlands
Poland
Romania
Slovakia
Ukraine
United States
Figure 1: Countries with Targeted Entities
Initial Access TTPs
To gain initial access to targeted entities, unit 26165 actors used several techniques to gain initial access to targeted entities, including (but not limited to):
Credential guessing [T1110.001] / brute force [T1110.003]
Spearphishing for credentials [T1566]
Spearphishing delivering malware [T1566]
Outlook NTLM vulnerability (CVE-2023-23397)
Roundcube vulnerabilities (CVE-2020-12641, CVE-2020-35730, CVE-2021-44026)
Exploitation of Internet-facing infrastructure, including corporate VPNs [T1133], via public vulnerabilities and SQL injection [T1190]
Exploitation of WinRAR vulnerability (CVE-2023-38831)
The actors abused vulnerabilities associated with a range of brands and models of small office/home office (SOHO) devices to facilitate covert cyber operations, as well as proxy malicious activity via devices with geolocation in proximity to the target [T1665]. [2]
Credential Guessing/Brute Force
Unit 26165 actors’ credential guessing [T1110.001] operations in this campaign exhibit some similar characteristics to those disclosed in the previous CSA “Russian GRU Conducting Global Brute Force Campaign to Compromise Enterprise and Cloud Environments.” [3] Based on victim network investigations, the current iteration of this TTP employs a similar blend of anonymization infrastructure, including the use of Tor and commercial VPNs [T1090.003]. The actors frequently rotated the IP addresses used to further hamper detection. All observed connections were made via encrypted TLS [T1573].
Spearphishing
GRU unit 26165 actors’ spearphishing emails included links [T1566.002] leading to fake login pages impersonating a variety of government entities and Western cloud email providers’ webpages. These webpages were typically hosted on free third-party services or compromised SOHO devices and often used legitimate documents associated with thematically similar entities as lures. The subjects of spearphishing emails were diverse and ranged from professional topics to adult themes. Phishing emails were frequently sent via compromised accounts or free webmail accounts [T1586.002, T1586.003]. The emails were typically written in the target’s native language and sent to a single targeted recipient.
Some campaigns employed multi-stage redirectors [T1104] verifying IP-geolocation [T1627.001] and browser fingerprints [T1627] to protect credential harvesting infrastructure or provide multifactor authentication (MFA) [T1111] and CAPTCHA relaying capabilities [T1056]. Connecting endpoints failing the location checks were redirected to a benign URL [T1627], such as msn.com. Redirector services used include:
The actors also used spearphishing to deliver malware (including HEADLACE and MASEPIE) executables [T1204.002] delivered via third-party services and redirectors [T1566.002], scripts in a mix of languages [T1059] (including BAT [T1059.003] and VBScript [T1059.005]) and links to hosted shortcuts [T1204.001].
CVE Usage
Throughout this campaign, GRU unit 26165 weaponized an Outlook NTLM vulnerability (CVE-2023-23397) to collect NTLM hashes and credentials via specially crafted Outlook calendar appointment invitations [T1187]. [4],[5] These actors also used a series of Roundcube CVEs (CVE-2020-12641, CVE-2020-35730, and CVE-2021-44026) to execute arbitrary shell commands [T1059], gain access to victim email accounts, and retrieve sensitive data from email servers [T1114].
Since at least fall 2023, the actors leveraged a WinRAR vulnerability (CVE-2023-38831) allowing for the execution of arbitrary code embedded in an archive as a means of initial access [T1659]. The actors sent emails with malicious attachments [T1566.001] or embedded hyperlinks [T1566.002] that downloaded a malicious archive prepared using this CVE.
Post-Compromise TTPs
After an initial compromise using one of the above techniques, unit 26165 actors conducted contact information reconnaissance to identify additional targets in key positions [T1589.002]. The actors also conducted reconnaissance of the cybersecurity department [T1591], individuals responsible for coordinating transport [T1591.004], and other companies cooperating with the victim entity [T1591.002].
The actors used native commands and open source tools, such as Impacket and PsExec, to move laterally within the environment [TA0008]. Multiple Impacket scripts were used as .exe files, in addition to the python versions, depending on the victim environment. The actors also moved laterally within the network using Remote Desktop Protocol (RDP) [T1021.001] to access additional hosts and attempt to dump Active Directory NTDS.dit domain databases [T1003.003] using native Active Directory Domain Services commands, such as in Figure 2: Example Active Directory Domain Services command:
C:Windowssystem32ntdsutil.exe “activate instance ntds” ifm “create full C:temp[a-z]{3}” quit quit
Figure 2: Example Active Directory Domain Services command
Additionally, GRU unit 26165 actors used the tools Certipy and ADExplorer.exe to exfiltrate information from the Active Directory. The actors installed python [T1059.006] on infected machines to enable the execution of Certipy. Accessed files were archived in .zip files prior to exfiltration [T1560]. The actors attempted to exfiltrate archived data via a previously dropped OpenSSH binary [T1048].
Incident response investigations revealed that the actors would take steps to locate and exfiltrate lists of Office 365 users and set up sustained email collection. The actors used manipulation of mailbox permissions [T1098.002] to establish sustained email collection at compromised logistics entities, as detailed in a Polish Cybercommand blog. [6]
After initial authentication, unit 26165 actors would change accounts’ folder permissions and enroll compromised accounts in MFA mechanisms to increase the trust-level of compromised accounts and enable sustained access [T1556.006]. The actors leveraged python scripts to retrieve plaintext passwords via Group Policy Preferences [T1552.006] using Get-GPPPassword.py and a modified ldap-dump.py to enumerate the Windows environment [T1087.002] and conduct a brute force password spray [T1110.003] via Lightweight Directory Access Protocol (LDAP). The actors would additionally delete event logs through the wevtutil utility [T1070.001].
After gaining initial access to the network, the actors pursued further access to accounts with access to sensitive information on shipments, such as train schedules and shipping manifests. These accounts contained information on aid shipments to Ukraine, including:
sender,
recipient,
train/plane/ship numbers,
point of departure,
destination,
container registration numbers,
travel route, and
cargo contents.
In at least one instance, the actors attempted to use voice phishing [T1566.004] to gain access to privileged accounts by impersonating IT staff.
Malware
Unit 26165’s use of malware in this campaign ranged from gaining initial access to establishing persistence and exfiltrating data. In some cases, the attack chain resulted in multiple pieces of malware being deployed in succession. The actors used dynamic link library (DLL) search order hijacking [T1574.001] to facilitate malware execution. There were a number of known malware variants tied to this campaign against logistics sector victims, including:
HEADLACE [7]
MASEPIE [8]
While other malware variants, such as OCEANMAP and STEELHOOK, [8] were not directly observed targeting logistics or IT entities, their deployment against victims in other sectors in Ukraine and other Western countries suggest that they could be deployed against logistics and IT entities should the need arise.
Persistence
In addition to the abovementioned mailbox permissions abuse, unit 26165 actors also used scheduled tasks [T1053.005], run keys [T1547.001], and placed malicious shortcuts [T1547.009] in the startup folder to establish persistence.
Exfiltration
GRU unit 26165 actors used a variety of methods for data exfiltration that varied based on the victim environment, including both malware and living off the land binaries. PowerShell commands [T1059.001] were often used to prepare data for exfiltration; for example, the actors prepared zip archives [T1560.001] for upload to their own infrastructure.
The actors also used server data exchange protocols and Application Programming Interfaces (APIs) such as Exchange Web Services (EWS) and Internet Message Access Protocol (IMAP) [T1114.002] to exfiltrate data from email servers. In multiple instances, the actors used periodic EWS queries [T1119] to collect new emails sent and received since the last data exfiltration [T1029]. The actors typically used infrastructure in close geographic proximity to the victim. Long gaps between exfiltration, the use of trusted and legitimate protocols, and the use of local infrastructure allowed for long-term collection of sensitive data to go undetected.
Connections to Targeting of IP Cameras
In addition to targeting logistics entities, unit 26165 actors likely used access to private cameras at key locations, such as near border crossings, military installations, and rail stations, to track the movement of materials into Ukraine. The actors also used legitimate municipal services, such as traffic cams.
The actors targeted Real Time Streaming Protocol (RTSP) servers hosting IP cameras primarily located in Ukraine as early as March 2022 in a large-scale campaign, which included attempts to enumerate devices [T1592] and gain access to the cameras’ feeds [T1125]. Actor-controlled servers sent RTSP DESCRIBE requests destined for RTSP servers, primarily hosting IP cameras [T1090.002]. The DESCRIBE requests were crafted to obtain access to IP cameras located on logically distinct networks from that of the routers that received the request. The requests included Base64-encoded credentials for the RTSP server, which included publicly documented default credentials and likely generic attempts to brute force access to the devices [T1110]. An example of an RTSP request is shown in Figure 3.
DESCRIBE rtsp://[IP ADDRESS] RTSP/1.0
CSeq: 2
Authorization: Digest username=”admin”, realm=”[a-f0-9]{12}”, algorithm=”MD5″, nonce=”[a-f0-9]{32}”, uri=””, response=”[a-f0-9]{32}”
User-Agent: WebClient
Accept: application/sdp
Figure 3: Example RTSP request
Successful RTSP 200 OK responses contained a snapshot of the IP camera’s image and IP camera metadata such as video codec, resolution, and other properties depending on the IP camera’s configuration.
From a sample available to the authoring agencies of over 10,000 cameras targeted via this effort, the geographic distribution of victims showed a strong focus on cameras in Ukraine and border countries, as shown in Table 1:
Table 1: Geographic distribution of targeted IP cameras
Country
Percentage of Total Attempts
Ukraine
81.0%
Romania
9.9%
Poland
4.0%
Hungary
2.8%
Slovakia
1.7%
Others
0.6%
Mitigation Actions
General Security Mitigations
Architecture and Configuration
Employ appropriate network segmentation [D3-NI] and restrictions to limit access and utilize additional attributes (such as device information, environment, and access path) when making access decisions [D3-AMED].
Consider Zero Trust principles when designing systems. Base product choices on how those products can solve specific risks identified as part of the end-to-end design. [9]
Ensure that host firewalls and network security appliances (e.g., firewalls) are configured to only allow legitimately needed data flows between devices and servers to prevent lateral movement [D3-ITF]. Alert on attempts to connect laterally between host devices or other unusual data flows.
Use automated tools to audit access logs for security concerns and identify anomalous access requests [D3-RAPA].
For organizations using on-premises authentication and email services, block and alert on NTLM/SMB requests to external infrastructure [D3-OTF].
Utilize endpoint, detection, and response (EDR) and other cybersecurity solutions on all systems, prioritizing high value systems with large amounts of sensitive data such as mail servers and domain controllers [D3-PM] first.
Perform threat and attack modeling to understand how sensitive systems may be compromised within an organization’s specific architecture and security controls. Use this to develop a monitoring strategy to detect compromise attempts and select appropriate products to enact this strategy.
Collect and monitor Windows logs for certain events, especially for events that indicate that a log was cleared unexpectedly [D3-SFA].
Enable optional security features in Windows to harden endpoints and mitigate initial access techniques [D3-AH]:
Enable attack surface reduction rules to prevent executable content from email [D3-ABPI].
Enable attack surface reduction rules to prevent execution of files from globally writeable directories, such as Downloads or %APPDATA% [D3-EAL].
Unless users are involved in the development of scripts, limit the local execution of scripts (such as batch scripts, VBScript, JScript/JavaScript, and PowerShell [10]) to known scripts [D3-EI], and audit execution attempts.
Disable Windows Host Scripting functionality and configure PowerShell to run in Constrained mode [D3-ACH].
Where feasible, implement allowlisting for applications and scripts to limit execution to only those needed for authorized activities, blocking all others by default [D3-EAL].
Consider using open source SIGMA rules as a baseline for detecting and alerting on suspicious file execution or command parameters [D3-PSA].
Use services that provide enhanced browsing services and safe link checking [D3-URA]. Significant reductions in successful spearphishing attempts were noted when email providers began offering link checking and automatic file detonation to block malicious content.
Where possible, block logins from public VPNs, including exit nodes in the same country as target systems, or, if they need to be allowed, alert on them for further investigation. Most organizations should not need to allow incoming traffic, especially logins to systems, from VPN services [D3-NAM].
Educate users to only use approved corporate systems for relevant government and military business and avoid the use of personal accounts on cloud email providers to conduct official business. Network administrators should also audit both email and web request logs to detect such activity.
Many organizations may not need to allow outgoing traffic to hosting and API mocking services, which are frequently used by GRU unit 26165. Organizations should consider alerting on or blocking the following services, with exceptions allowlisted for legitimate activity [D3-DNSDL].
Heuristic detections for web requests to new subdomains, including of the above providers, may uncover malicious phishing activity [D3-DNRA]. Logging the requests for each sub-domain requested by users on a network, such as in DNS or firewall logs, may enable system administrators to identify new targeting and victims.
Identity and Access Management
Organizations should take measures to ensure strong access controls and mitigate against common credential theft techniques:
Use MFA with strong factors, such as passkeys or PKI smartcards, and require regular re-authentication [D3-MFA]. [11], [12] Strong authentication factors are not guessable using dictionary techniques, so they resist brute force attempts.
Implement other mitigations for privileged accounts: including limiting the number of admin accounts, considering using hardware MFA tokens, and regularly reviewing all privileged user accounts [D3-JFAPA].
Separate privileged accounts by role and alert on misuse of privileged accounts [D3-UAP]. For example, email administrator accounts should be different from domain administrator accounts.
Reduce reliance on passwords; instead, consider using services like single sign-on [D3-TBA].
For organizations using on-premises authentication and email services, plan to disable NTLM entirely and migrate to more robust authentication processes such as PKI certificate authentication.
Do not store passwords in Group Policy Preferences (GPP). Remove all passwords previously included in GPP and change all passwords on the corresponding accounts [D3-CH]. [13]
Use account throttling or account lockout [D3-ANET]:
Throttling is preferred to lockout. Throttling progressively increases time delay between successive login attempts.
Account lockout can leave legitimate users unable to access their accounts and requires access to an account recovery process.
Account lockout can provide a malicious actor with an easy way to launch a Denial of Service (DoS).
If using lockout, then allowing 5 to 10 attempts before lockout is recommended.
Use a service to check for compromised passwords before using them [D3-SPP]. For example, “Have I Been Pwned” can be used to check whether a password has been previously compromised without disclosing the potential password.
Change all default credentials [D3-CRO] and disable protocols that use weak authentication (e.g., clear-text passwords or outdated and vulnerable authentication or encryption protocols) or do not support multi-factor authentication [D3-ACH] [D3-ET]. Always configure access controls carefully to ensure that only well-maintained and well-authenticated accounts have access. [13]
IP Camera Mitigations
The following mitigation techniques for IP cameras can be used to defend against this type of malicious activity:
Ensure IP cameras are currently supported. Replace devices that are out of support.
Apply security patches and firmware updates to all IP cameras [D3-SU].
Disable remote access to the IP camera, if unnecessary [D3-ITF].
Ensure cameras are protected by a security appliance, if possible, such as by using a firewall to prevent communication with the camera from IP addresses not on an allowlist [D3-NAM].
If remote access to IP camera feeds is required, ensure authentication is enabled [D3-AA] and use a VPN to connect remotely [D3-ET]. Use MFA for management accounts if supported [D3-MFA].
Disable Universal Plug and Play (UPnP), Peer-to-Peer (P2P), and Anonymous Visit features on IP cameras and routers [D3-NI].
Turn off other ports/services not in use (e.g., FTP, web interface, etc.) [D3-ACH].
If supported, enable authenticated RTSP access only [D3-AA].
Review all authentication activity for remote access to make sure it is valid and expected [D3-UBA]. Investigate any unexpected or unusual activity.
Audit IP camera user accounts to ensure they are an accurate reflection of your organization and that they are being used as expected [D3-UAP].
Configure, tune, and monitor logging—if available—on the IP camera.
Indicators of Compromise (IOCs)
Note: Specific IoCs may no longer be actor controlled, may themselves be compromised infrastructure or email accounts, or may be shared infrastructure such as public VPN or Tor exit nodes. Care should be taken when basing triaging logs or developing detection rules on these indicators. GRU unit 26165 almost certainly uses extensive further infrastructure and TTPs not specifically listed in this report.
Utilities and scripts
Legitimate utilities
Unauthorized or unusual use of the following legitimate utilities can be an indication of a potential compromise:
ntdsutil – A legitimate Windows executable used by threat actors to export contents of Active Directory
wevtutil – A legitimate Windows executable used by threat actors to delete event logs
vssadmin – A legitimate Windows executable possibly used by threat actors to make a copy of the server’s C: drive
ADexplorer – A legitimate window executable to view, edit, and backup Active Directory Certificate Services
OpenSSH – The Windows version of a legitimate open source SSH client
schtasks – A legitimate Windows executable used to create persistence using scheduled tasks
whoami – A legitimate Windows executable used to retrieve the name of the current user
tasklist – A legitimate Windows executable used to retrieve the list of running processes
hostname – A legitimate Windows executable used to retrieve the device name
arp – A legitimate Windows executable used to retrieve the ARP table for mapping the network environment
systeminfo – A legitimate Windows executable used to retrieve a comprehensive summary of device and operating system information
net – A legitimate Windows executable used to retrieve detailed user information
wmic – A legitimate Windows executable used to interact with Windows Management Instrumentation (WMI), such as to retrieve letters assigned to logical partitions on storage drives
cacls – A legitimate Windows executable used to modify permissions on files
icacls – A legitimate Windows executable used to modify permissions to files and handle integrity levels and ownership
ssh – A legitimate Windows executable used to establish network shell connections
reg – A legitimate Windows executable used to add to or modify the system registry
Note: Additional heuristics are needed for effective hunting for these and other living off the land (LOTL) binaries to avoid being overwhelmed by false positives if these legitimate management tools are used regularly. See the joint guide, Identifying and Mitigating Living Off the Land Techniques, for guidance on developing a multifaceted cybersecurity strategy that enables behavior analytics, anomaly detection, and proactive hunting, which are part of a comprehensive approach to mitigating cyber threats that employ LOTL techniques.
Malicious scripts
Certipy – An open source python tool for enumerating and abusing Active Directory Certificate Services
Get-GPPPassword.py – An open source python script for finding insecure passwords stored in Group Policy Preferences
ldap-dump.py – A script for enumerating user accounts and other information in Active Directory
Hikvision backdoor string: “YWRtaW46MTEK”
Suspicious command lines
While the following utilities are legitimate, and using them with the command lines shown may also be legitimate, these command lines are often used during malicious activities and could be an indication of a compromise:
Brute Forcing IP Addresses
Disclaimer: These IP addresses date June 2024 through August 2024. The authoring agencies recommend organizations investigate or vet these IP addresses prior to taking action, such as blocking.
condition:
(
( uint16( 0x0 ) ==0x5a4d )
and
( uint16( uint32( 0x3c )) == 0x4550 )
)
and
filesize < 1024KB
and
(
( any of ($sysinternals_*) and any of ($psexec_*) )
or
( 2 of ($network_*) and 2 of ($psexec_*))
)
}
Cybersecurity Industry Tracking
The cybersecurity industry provides overlapping cyber threat intelligence, IOCs, and mitigation recommendations related to GRU unit 26165 cyber actors. While not all encompassing, the following are the most notable threat group names related under MITRE ATT&CK G0007 and commonly used within the cybersecurity community:
Note: Cybersecurity companies have different methods of tracking and attributing cyber actors, and this may not be a 1:1 correlation to the U.S. government’s understanding for all activity related to these groupings.
Further Reference
To search for the presence of malicious email messages targeting CVE-2023-23397, network defenders may consider using the script published by Microsoft: https://aka.ms/CVE-2023-23397ScriptDoc.
For the Impacket TTP, network defenders may consider using the following publicly available Impacket YARA detection rule:https://github.com/Neo23x0/signature-base/blob/master/yara/gen_impacket_tools.yar
Works Cited
[1] Microsoft. Defending Ukraine: Early Lessons from the Cyber War. 2022. https://blogs.microsoft.com/on-the-issues/2022/06/22/defending-ukraine-early-lessons-from-the-cyber-war/ [2] FBI et al. Russian Cyber Actors Use Compromised Routers to Facilitate Cyber Operations. 2024. https://media.defense.gov/2024/Feb/27/2003400753/-1/-1/0/CSA-Russian-Actors-Use-Routers-Facilitate-Cyber_Operations.PDF [3] NSA et al. Russian GRU Conducting Global Brute Force Campaign to Compromise Enterprise and Cloud Environments. 2021. https://media.defense.gov/2021/Jul/01/2002753896/-1/-1/0/CSA_GRU_GLOBAL_BRUTE_FORCE_CAMPAIGN_UOO158036-21.PDF [4] ANSSI. Campagnes d’attaques du mode opératoire APT28 depuis 2021. 2023. https://cert.ssi.gouv.fr/cti/CERTFR-2023-CTI-009/ [5] ANSSI. Targeting and compromise of french entities using the APT28 intrusion set. 2025. https://cert.ssi.gouv.fr/cti/CERTFR-2025-CTI-007/ [6] Polish Cyber Command. Detecting Malicious Activity Against Microsoft Exchange Servers. 2023. https://www.wojsko-polskie.pl/woc/articles/aktualnosci-w/detecting-malicious-activity-against-microsoft-exchange-servers/ [7] IBM. Israel-Hamas Conflict Lures to Deliver Headlace Malware. 2023. https://securityintelligence.com/x-force/itg05-ops-leverage-israel-hamas-conflict-lures-to-deliver-headlace-malware/ [8] CERT-UA. APT28: From Initial Attack to Creating Domain Controller Threats in an Hour. 2023. https://cert.gov.ua/article/6276894 [9] NSA. Embracing a Zero Trust Security Model. 2021. https://media.defense.gov/2021/Feb/25/2002588479/-1/-1/0/CSI_EMBRACING_ZT_SECURITY_MODEL_UOO115131-21.PDF [10] NSA et al. Keeping PowerShell: Security Measures to Use and Embrace. 2022. https://media.defense.gov/2022/Jun/22/2003021689/-1/-1/0/CSI_KEEPING_POWERSHELL_SECURITY_MEASURES_TO_USE_AND_EMBRACE_20220622.PDF [11] National Institute of Standards and Technology (NIST). Special Publication 800-63B: Digital Identity Guidelines – Authentication and Lifecycle Management. 2020. https://pages.nist.gov/800-63-3/sp800-63b.html [12] NSA. Selecting Secure Multi-factor Authentication Solutions. October 16, 2020. https://media.defense.gov/2024/Jul/31/2003515137/-1/-1/0/MULTIFACTOR_AUTHENTICATION_SOLUTIONS_UOO17091520.PDF [13] NSA and CSA. NSA and CISA Red and Blue Teams Share Top Ten Cybersecurity Misconfigurations. 2023. https://media.defense.gov/2023/Oct/05/2003314578/-1/-1/0/JOINT_CSA_TOP_TEN_MISCONFIGURATIONS_TLP-CLEAR.PDF
[14] Department of Justice. Justice Department Conducts Court-Authorized Disruption of Botnet Controlled by the Russian Federation’s Main Intelligence Directorate of the General Staff (GRU). 2024. https://www.justice.gov/archives/opa/pr/justice-department-conducts-court-authorized-disruption-botnet-controlled-russian [15] Recorded Future. GRU’s BlueDelta Targets Key Networks in Europe with Multi-Phase Espionage Campaigns. 2024. https://go.recordedfuture.com/hubfs/reports/CTA-RU-2024-0530.pdf
Disclaimer of endorsement
The information and opinions contained in this document are provided “as is” and without any warranties or guarantees. Reference herein to any specific commercial products, process, or service by trade name, trademark, manufacturer, or otherwise, does not constitute or imply its endorsement, recommendation, or favoring by the United States Government, and this guidance shall not be used for advertising or product endorsement purposes.
Purpose
This document was developed in furtherance of the authoring agencies’ cybersecurity missions, including their responsibilities to identify and disseminate threats and to develop and issue cybersecurity specifications and mitigations. This information may be shared broadly to reach all appropriate stakeholders.
Contact
United States organizations
National Security Agency (NSA)
Cybersecurity Report Feedback: CybersecurityReports@nsa.gov
Defense Industrial Base Inquiries and Cybersecurity Services: DIB_Defense@cyber.nsa.gov
Media Inquiries / Press Desk: NSA Media Relations: 443-634-0721, MediaRelations@nsa.gov
Cybersecurity and Infrastructure Security Agency (CISA) and Federal Bureau of Investigation (FBI)
U.S. organizations are encouraged to reporting suspicious or criminal activity related to information in this advisory to CISA via the agency’s Incident Reporting System, its 24/7 Operations Center (report@cisa.gov or 888-282-0870), or your local FBI field office. When available, please include the following information regarding the incident: date, time, and location of the incident; type of activity; number of people affected; type of equipment user for the activity; the name of the submitting company or organization; and a designated point of contact.
Department of Defense Cyber Crime Center (DC3)
Defense Industrial Base Inquiries and Cybersecurity Services: DC3.DCISE@us.af.mil
Media Inquiries / Press Desk: DC3.Information@us.af.mil
United Kingdom organizations
Report significant cyber security incidents to ncsc.gov.uk/report-an-incident (monitored 24/7)
Security Information Service (BIS): cyber.threats@bis.cz
National Cyber and Information Security Agency (NÚKIB): cert.incident@nukib.gov.cz
Poland organizations
Poland Military Counterintelligence Service (SKW): cyber.int@skw.gov.pl
Australian organizations
Visit cyber.gov.au or call 1300 292 371 (1300 CYBER 1) to report cybersecurity incidents and access alerts and advisories.
Canadian organizations
Report incidents by emailing CCCS at contact@cyber.gc.ca.
Estonia organizations
Estonian Foreign Intelligence Service (EFIS): info@valisluureamet.ee
Estonian National Cyber Security Centre (NCSC-EE): ria@ria.ee
French organizations
French organizations are encouraged to report suspicious activity or incident related to information found in this advisory by contacting ANSSI/CERT-FR by email at cert-fr@ssi.gouv.fr or by phone at: 3218 or +33 9 70 83 32 18.
Appendix A: MITRE ATT&CK tactics and techniques
See Table 2 through Table 14 for all the threat actor tactics and techniques referenced in this advisory.
Table 2: Reconnaissance
Tactic/Technique Title
ID
Use
Reconnaissance
TA0043
Conducted reconnaissance on at least one entity involved in the production of ICS components for railway management.
Gather Victim Identity Information: Email Addresses
T1589.002
Conducted contact information reconnaissance to identify additional targets in key positions.
Gather Victim Org Information
T1591
Conducted reconnaissance of the cybersecurity department.
Gather Victim Org Information: Identify Roles
T1591.004
Conducted reconnaissance of individuals responsible for coordinating transport.
Gather Victim Org Information: Business Relationships
T1591.002
Conducted reconnaissance of other companies cooperating with the victim entity.
Gather Victim Host Information
T1592
Attempted to enumerate Real Time Streaming Protocol (RTSP) servers hosting IP cameras.
Table 3: Resource development
Tactic/Technique Title
ID
Use
Compromise Accounts: Email Accounts
T1586.002
Sent phishing emails using compromised accounts.
Compromise Accounts: Cloud Accounts
T1586.003
Sent phishing emails using compromised accounts.
Table 4: Initial Access
Tactic/Technique Title
ID
Use
Trusted Relationship
T1199
Conducted follow-on targeting of additional entities in the transportation sector that had business ties to the primary target, exploiting trust relationships to attempt to gain additional access.
Phishing
T1566
Used spearphishing for credentials and delivering malware to gain initial access to targeted entities.
Phishing: Spearphishing Attachment
T1566.001
Sent emails with malicious attachments.
Phishing: Spearphishing Link
T1566.002
Used spearphishing with included links to fake login pages. Sent emails with embedded hyperlinks that downloaded a malicious archive.
Phishing: Spearphishing Voice
T1566.004
Attempted to use voice phishing to gain access to privileged accounts by impersonating IT staff.
External Remote Services
T1133
Exploited Internet-facing infrastructure, including corporate VPNs, to gain initial access to targeted entities.
Exploit Public-Facing Application
T1190
Exploited public vulnerabilities and SQL injection to gain initial access to targeted entities.
Content Injection
T1659
Leveraged a WinRAR vulnerability allowing for the execution of arbitrary code embedded in an archive.
Table 5: Execution
Tactic/Technique Title
ID
Use
User Execution: Malicious Link
T1204.001
Used malicious links to hosted shortcuts in spearphishing.
User Execution: Malicious File
T1204.002
Delivered malware executables via spearphishing.
Scheduled Task/Job: Scheduled Task
T1053.005
Used scheduled tasks to establish persistence.
Command and Scripting Interpreter
T1059
Delivered scripts in spearphishing. Executed arbitrary shell commands.
Command and Scripting Interpreter: PowerShell
T1059.001
PowerShell commands were often used to prepare data for exfiltration.
Command and Scripting Interpreter: Windows Command Shell
T1059.003
Used BAT script in spearphishing.
Command and Scripting Interpreter: Visual Basic
T1059.005
Used VBScript in spearphishing.
Command and Scripting Interpreter: Python
T1059.006
Installed python on infected machines to enable the execution of Certipy.
Enrolled compromised accounts in MFA mechanisms to increase the trust-level of compromised accounts and enable sustained access.
Hijack Execution Flow: DLL Search Order Hijacking
T1574.001
Used DLL search order hijacking to facilitate malware execution.
Boot or Logon Autostart Execution: Registry Run Keys / Startup Folder
T1547.001
Used run keys to establish persistence.
Boot or Logon Autostart Execution: Shortcut Modification
T1547.009
Placed malicious shortcuts in the startup folder to establish persistence.
Table 7: Defense Evasion
Tactic/Technique Title
ID
Use
Indicator Removal: Clear Windows Event Logs
T1070.001
Deleted event logs through the wevtutil utility.
Table 8: Credential access
Tactic/Technique Title
ID
Use
Brute Force
T1110
Sent requests with Base64-encoded credentials for the RTSP server, which included publicly documented default credentials, and likely were generic attempts to brute force access to the devices.
Brute Force: Password Guessing
T1110.001
Used credential guessing to gain initial access to targeted entities.
Brute Force: Password Spraying
T1110.003
Used brute force to gain initial access to targeted entities. Conducted a brute force password spray via LDAP.
Multi-Factor Authentication Interception
T1111
Used multi-stage redirectors to provide MFA relaying capabilities in some campaigns.
Input Capture
T1056
Used multi-stage redirectors to provide CAPTCHA relaying capabilities in some campaigns.
Forced Authentication
T1187
Used an Outlook NTLM vulnerability to collect NTLM hashes and credentials via specially crafted Outlook calendar appointment invitations.
OS Credential Dumping: NTDS
T1003.003
Attempted to dump Active Directory NTDS.dit domain databases.
Unsecured Credentials: Group Policy Preferences
T1552.006
Retrieved plaintext passwords via Group Policy Preferences using Get-GPPPassword.py.
Table 9: Discovery
Tactic/Technique Title
ID
Use
Account Discovery: Domain Account
T1087.002
Used a modified ldap-dump.py to enumerate the Windows environment.
Table 10: Command and Control
Tactic/Technique Title
ID
Use
Hide Infrastructure
T1665
Abused SOHO devices to facilitate covert cyber operations, as well as proxy malicious activity, via devices with geolocation in proximity to the target.
Proxy: External Proxy
T1090.002
Actor-controlled servers sent RTSP DESCRIBE requests destined for RTSP servers.
Proxy: Multi-hop Proxy
T1090.003
Used Tor and commercial VPNs as part of their anonymization infrastructure
Encrypted Channel
T1573
Connected to victim infrastructure using encrypted TLS.
Multi-Stage Channels
T1104
Used multi-stage redirectors for campaigns.
Table 11: Defense evasion (mobile framework)
Tactic/Technique Title
ID
Use
Execution Guardrails
T1627
Used multi-stage redirectors to verify browser fingerprints in some campaigns.
Execution Guardrails: Geofencing
T1627.001
Used multi-stage redirectors to verify IP-geolocation in some campaigns.
Table 12: Lateral movement
Tactic/Technique Title
ID
Use
Lateral Movement
TA0008
Used native commands and open source tools, such as Impacket and PsExec, to move laterally within the environment.
Remote Services: Remote Desktop Protocol
T1021.001
Moved laterally within the network using RDP.
Table 13: Collection
Tactic/Technique Title
ID
Use
Email Collection
T1114
Retrieved sensitive data from email servers.
Email Collection: Remote Email Collection
T1114.002
Used server data exchange protocols and APIs such as Exchange Web Services (EWS) and IMAP to exfiltrate data from email servers.
Automated Collection
T1119
Used periodic EWS queries to collect new emails.
Video Capture
T1125
Attempted to gain access to the cameras’ feeds.
Archive Collected Data
T1560
Accessed files were archived in .zip files prior to exfiltration.
Archive Collected Data: Archive via Utility
T1560.001
Prepared zip archives for upload to the actors’ infrastructure.
Table 14: Exfiltration
Tactic/Technique Title
ID
Use
Exfiltration Over Alternative Protocol
T1048
Attempted to exfiltrate archived data via a previously dropped OpenSSH binary.
Scheduled Transfer
T1029
Used periodic EWS queries to collect new emails sent and received since the last data exfiltration.
Appendix B: CVEs exploited
Table 15: Exploited CVE information
CVE
Vendor/Product
Details
CVE-2023-38831
RARLAB WinRAR
Allows execution of arbitrary code when a user attempts to view a benign file within a ZIP archive.
CVE-2023-23397
Microsoft Outlook
External actors could send specially crafted emails that cause a connection from the victim to an untrusted location of the actor’s control, leaking the Net-NTLMv2 hash of the victim that the actor could then relay to another service to authenticate as the victim.
CVE-2021-44026
Roundcube Webmail
Roundcube before 1.3.17 and 1.4.x before 1.4.12 is prone to a potential SQL injection via search or search params.
CVE-2020-35730
Roundcube Webmail
An XSS issue was discovered in Roundcube Webmail before 1.2.13, 1.3.x before 1.3.16 and 1.4.x before 1.4.10, where a plaintext email message with JavaScript in a link reference element is mishandled by linkref_addindex in rcube_string_replacer.php.
CVE-2020-12641
Roundcube Webmail
Roundcube Webmail before 1.4.4 allows arbitrary code execution via shell metacharacters in a configuration setting for im_convert_path or im_identify_path in rcube_image.php.
Appendix C: MITRE D3FEND Countermeasures
Table 16: MITRE D3FEND countermeasures
Countermeasure Title
ID
Details
Network Isolation
D3-NI
Employ appropriate network segmentation. Disable Universal Plug and Play (UPnP), Peer-to-Peer (P2P), and Anonymous Visit features on IP cameras and routers.
Access Mediation
D3-AMED
Limit access and utilize additional attributes (such as device information, environment, and access path) when making access decisions. Configure access controls carefully to ensure that only well-maintained and well-authenticated accounts have access.
Inbound Traffic Filtering
D3-ITF
Implement host firewall rules to block connections from other devices on the network, other than from authorized management devices and servers, to prevent lateral movement.
Resource Access Pattern Analysis
D3-RAPA
Use automated tools to audit access logs for security concerns and identify anomalous access requests.
Outbound Traffic Filtering
D3-OTF
Block NTLM/SMB requests to external infrastructure.
Platform Monitoring
D3-PM
Install EDR/logging/cybersecurity solutions onto high value systems with large amounts of sensitive data such as mail servers and domain controllers.
System File Analysis
D3-SFA
Collect and monitor Windows logs for certain events, especially for events that indicate that a log was cleared unexpectedly.
Application Hardening
D3-AH
Enable optional security features in Windows to harden endpoints and mitigate initial access techniques.
Application-based Process Isolation
D3-ABPI
Enable attack surface reduction rules to prevent executable content from email.
Executable Allowlisting
D3-EAL
Enable attack surface reduction rules to prevent execution of files from globally writeable directories, such as Downloads or %APPDATA%.
Execution Isolation
D3-EI
Unless users are involved in the development of scripts, limit the execution of scripts (such as batch, JavaScript, and PowerShell) to known scripts.
Application Configuration Hardening
D3-ACH
Disable Windows Host Scripting functionality and configure PowerShell to run in Constrained mode. Disable protocols that use weak authentication (e.g., clear-text passwords, or outdated and vulnerable authentication or encryption protocols) or do not support multi-factor authentication. Turn off other ports/services not in use (e.g., FTP, web interface, etc.).
Process Spawn Analysis
D3-PSA
Use open source SIGMA rules as a baseline for detecting and alerting on suspicious file execution or command parameters.
URL Reputation Analysis
D3-URA
Use services that provide enhanced browsing services and safe link checking.
Network Access Mediation
D3-NAM
Do not allow incoming traffic, especially logins to systems, from public VPN services. Where possible, logins from public VPNs, including exit nodes in the same country as target systems, should be blocked or, if allowed, alerted on for further investigation. Ensure cameras and other Internet of Things devices are protected by a security appliance, if possible.
DNS Denylisting
D3-DNSDL
Do not allow outgoing traffic to hosting and API mocking services frequently used by malicious actors.
Domain Name Reputation Analysis
D3-DNRA
Heuristic detections for web requests to new subdomains may uncover malicious phishing activity. Logging the requests for each sub-domain requested by users on a network, such as in DNS or firewall logs, may enable system administrators to identify new targeting and victims.
Multi-factor Authentication
D3-MFA
Use MFA with strong factors and require regular re-authentication, especially for management accounts.
Job Function Access Pattern Analysis
D3-JFAPA
Implement other mitigations for privileged accounts: including limiting the number of admin accounts, considering using hardware MFA tokens, and regularly reviewing all privileged user accounts.
User Account Permissions
D3-UAP
Separate privileged accounts by role and alert on misuse of privileged accounts. Audit user accounts on all devices to ensure they are an accurate reflection of your organization and that they are being used as expected.
Token-based Authentication
D3-TBA
Reduce reliance on passwords; instead, consider using services like single sign-on.
Credential Hardening
D3-CH
Do not store passwords in Group Policy Preferences (GPP). Remove all passwords previously included in GPP and change all passwords on the corresponding accounts.
Authentication Event Threshholding
D3-ANET
Use account throttling or account lockout. Throttling progressively increases time delay between successive login attempts. If using account lockout, allow between 5 to 10 attempts before lockout.
Strong Password Policy
D3-SPP
Use a service to check for compromised passwords before using them.
Credential Rotation
D3-CRO
Change all default credentials.
Encrypted Tunnels
D3-ET
Disable protocols that use weak authentication (e.g., clear-text passwords, or outdated and vulnerable authentication or encryption protocols). Use a VPN for remote connections to devices.
Software Update
D3-SU
Apply security patches and firmware updates to all devices. Ensure devices are currently supported. Replace devices that are end-of-life.
Agent Authentication
D3-AA
Ensure authentication is enabled for remote access to devices. If supported on IP cameras, enable authenticated RTSP access only.
User Behavior Analysis
D3-UBA
Review all authentication activity for remote access to make sure it is valid and expected. Investigate any unexpected or unusual activity.
Executive Summary
This joint cybersecurity advisory (CSA) highlights a Russian state-sponsored cyber campaign targeting Western logistics entities and technology companies. This includes those involved in the coordination, transport, and delivery of foreign assistance to Ukraine. Since 2022, Western logistics entities and IT companies have faced an elevated risk of targeting by the Russian General Staff Main Intelligence Directorate (GRU) 85th Main Special Service Center (85th GTsSS), military unit 26165—tracked in the cybersecurity community under several names (see “Cybersecurity Industry Tracking”). The actors’ cyber espionage-oriented campaign, targeting technology companies and logistics entities, uses a mix of previously disclosed tactics, techniques, and procedures (TTPs). The authoring agencies expect similar targeting and TTP use to continue.
Executives and network defenders at logistics entities and technology companies should recognize the elevated threat of unit 26165 targeting, increase monitoring and threat hunting for known TTPs and indicators of compromise (IOCs), and posture network defenses with a presumption of targeting.
This cyber espionage-oriented campaign targeting logistics entities and technology companies uses a mix of previously disclosed TTPs and is likely connected to these actors’ wide scale targeting of IP cameras in Ukraine and bordering NATO nations.
The following authors and co-sealers are releasing this CSA:
United States National Security Agency (NSA)
United States Federal Bureau of Investigation (FBI)
United Kingdom National Cyber Security Centre (NCSC-UK)
Germany Federal Intelligence Service (BND) Bundesnachrichtendienst
Germany Federal Office for Information Security (BSI) Bundesamt für Sicherheit in der Informationstechnik
Germany Federal Office for the Protection of the Constitution (BfV) Bundesamt für Verfassungsschutz
Czech Republic Military Intelligence (VZ) Vojenské zpravodajství
Czech Republic National Cyber and Information Security Agency (NÚKIB) Národní úřad pro kybernetickou a informační bezpečnost
Czech Republic Security Information Service (BIS) Bezpečnostní informační služba
Poland Internal Security Agency (ABW) Agencja Bezpieczeństwa Wewnętrznego
Poland Military Counterintelligence Service (SKW) Służba Kontrwywiadu Wojskowego
United States Cybersecurity and Infrastructure Security Agency (CISA)
United States Department of Defense Cyber Crime Center (DC3)
United States Cyber Command (USCYBERCOM)
Australian Signals Directorate’s Australian Cyber Security Centre (ASD’s ACSC)
Canadian Centre for Cyber Security (CCCS)
Danish Defence Intelligence Service (DDIS) Forsvarets Efterretningstjeneste
Estonian Foreign Intelligence Service (EFIS) Välisluureamet
Estonian National Cyber Security Centre (NCSC-EE) Küberturvalisuse keskus
French Cybersecurity Agency (ANSSI) Agence nationale de la sécurité des systèmes d’information
Netherlands Defence Intelligence and Security Service (MIVD) Militaire Inlichtingen- en Veiligheidsdienst
For over two years, the Russian GRU 85th GTsSS, military unit 26165—commonly known in the cybersecurity community as APT28, Fancy Bear, Forest Blizzard, BlueDelta, and a variety of other identifiers—has conducted this campaign using a mix of known tactics, techniques, and procedures (TTPs), including reconstituted password spraying capabilities, spearphishing, and modification of Microsoft Exchange mailbox permissions. In late February 2022, multiple Russian state-sponsored cyber actors increased the variety of cyber operations for purposes of espionage, destruction, and influence—with unit 26165 predominately involved in espionage. [1] As Russian military forces failed to meet their military objectives and Western countries provided aid to support Ukraine’s territorial defense, unit 26165 expanded its targeting of logistics entities and technology companies involved in the delivery of aid. These actors have also targeted Internet-connected cameras at Ukrainian border crossings to monitor and track aid shipments. Note: This advisory uses the MITRE ATT&CK® for Enterprise framework, version 17. See Appendix A: MITRE ATT&CK tactics and techniques for a table of the threat actors’ activity mapped to MITRE ATT&CK tactics and techniques. This advisory uses the MITRE D3FEND® framework, version 1.0.
Description of Targets
The GRU unit 26165 cyber campaign against Western logistics providers and technology companies has targeted dozens of entities, including government organizations and private/commercial entities across virtually all transportation modes: air, sea, and rail. These actors have targeted entities associated with the following verticals within NATO member states, Ukraine, and at international organizations:
Defense Industry
Transportation and Transportation Hubs (ports, airports, etc.)
Maritime
Air Traffic Management
IT Services
In the course of the targeting lifecycle, unit 26165 actors identified and conducted follow-on targeting of additional entities in the transportation sector that had business ties to the primary target, exploiting trust relationships to attempt to gain additional access [T1199].
The actors also conducted reconnaissance on at least one entity involved in the production of industrial control system (ICS) components for railway management, though a successful compromise was not confirmed [TA0043].
The countries with targeted entities include the following, as illustrated in Figure 1:
Bulgaria
Czech Republic
France
Germany
Greece
Italy
Moldova
Netherlands
Poland
Romania
Slovakia
Ukraine
United States
Figure 1: Countries with Targeted Entities
Initial Access TTPs
To gain initial access to targeted entities, unit 26165 actors used several techniques to gain initial access to targeted entities, including (but not limited to):
The actors abused vulnerabilities associated with a range of brands and models of small office/home office (SOHO) devices to facilitate covert cyber operations, as well as proxy malicious activity via devices with geolocation in proximity to the target [T1665]. [2]
Credential Guessing/Brute Force
Unit 26165 actors’ credential guessing [T1110.001] operations in this campaign exhibit some similar characteristics to those disclosed in the previous CSA “Russian GRU Conducting Global Brute Force Campaign to Compromise Enterprise and Cloud Environments.” [3] Based on victim network investigations, the current iteration of this TTP employs a similar blend of anonymization infrastructure, including the use of Tor and commercial VPNs [T1090.003]. The actors frequently rotated the IP addresses used to further hamper detection. All observed connections were made via encrypted TLS [T1573].
Spearphishing
GRU unit 26165 actors’ spearphishing emails included links [T1566.002] leading to fake login pages impersonating a variety of government entities and Western cloud email providers’ webpages. These webpages were typically hosted on free third-party services or compromised SOHO devices and often used legitimate documents associated with thematically similar entities as lures. The subjects of spearphishing emails were diverse and ranged from professional topics to adult themes. Phishing emails were frequently sent via compromised accounts or free webmail accounts [T1586.002, T1586.003]. The emails were typically written in the target’s native language and sent to a single targeted recipient.
Some campaigns employed multi-stage redirectors [T1104] verifying IP-geolocation [T1627.001] and browser fingerprints [T1627] to protect credential harvesting infrastructure or provide multifactor authentication (MFA) [T1111] and CAPTCHA relaying capabilities [T1056]. Connecting endpoints failing the location checks were redirected to a benign URL [T1627], such as msn.com. Redirector services used include:
Webhook[.]site
FrgeIO
InfinityFree
Dynu
Mocky
Pipedream
Mockbin[.]org
The actors also used spearphishing to deliver malware (including HEADLACE and MASEPIE) executables [T1204.002] delivered via third-party services and redirectors [T1566.002], scripts in a mix of languages [T1059] (including BAT [T1059.003] and VBScript [T1059.005]) and links to hosted shortcuts [T1204.001].
CVE Usage
Throughout this campaign, GRU unit 26165 weaponized an Outlook NTLM vulnerability (CVE-2023-23397) to collect NTLM hashes and credentials via specially crafted Outlook calendar appointment invitations [T1187]. [4],[5] These actors also used a series of Roundcube CVEs (CVE-2020-12641, CVE-2020-35730, and CVE-2021-44026) to execute arbitrary shell commands [T1059], gain access to victim email accounts, and retrieve sensitive data from email servers [T1114].
Since at least fall 2023, the actors leveraged a WinRAR vulnerability (CVE-2023-38831) allowing for the execution of arbitrary code embedded in an archive as a means of initial access [T1659]. The actors sent emails with malicious attachments [T1566.001] or embedded hyperlinks [T1566.002] that downloaded a malicious archive prepared using this CVE.
Post-Compromise TTPs
After an initial compromise using one of the above techniques, unit 26165 actors conducted contact information reconnaissance to identify additional targets in key positions [T1589.002]. The actors also conducted reconnaissance of the cybersecurity department [T1591], individuals responsible for coordinating transport [T1591.004], and other companies cooperating with the victim entity [T1591.002].
The actors used native commands and open source tools, such as Impacket and PsExec, to move laterally within the environment [TA0008]. Multiple Impacket scripts were used as .exe files, in addition to the python versions, depending on the victim environment. The actors also moved laterally within the network using Remote Desktop Protocol (RDP) [T1021.001] to access additional hosts and attempt to dump Active Directory NTDS.dit domain databases [T1003.003] using native Active Directory Domain Services commands, such as in Figure 2: Example Active Directory Domain Services command:
C:Windowssystem32ntdsutil.exe "activate instance ntds" ifm "create full C:temp[a-z]{3}" quit quit
Figure 2: Example Active Directory Domain Services command
Additionally, GRU unit 26165 actors used the tools Certipy and ADExplorer.exe to exfiltrate information from the Active Directory. The actors installed python [T1059.006] on infected machines to enable the execution of Certipy. Accessed files were archived in .zip files prior to exfiltration [T1560]. The actors attempted to exfiltrate archived data via a previously dropped OpenSSH binary [T1048].
Incident response investigations revealed that the actors would take steps to locate and exfiltrate lists of Office 365 users and set up sustained email collection. The actors used manipulation of mailbox permissions [T1098.002] to establish sustained email collection at compromised logistics entities, as detailed in a Polish Cybercommand blog. [6]
After initial authentication, unit 26165 actors would change accounts’ folder permissions and enroll compromised accounts in MFA mechanisms to increase the trust-level of compromised accounts and enable sustained access [T1556.006]. The actors leveraged python scripts to retrieve plaintext passwords via Group Policy Preferences [T1552.006] using Get-GPPPassword.py and a modified ldap-dump.py to enumerate the Windows environment [T1087.002] and conduct a brute force password spray [T1110.003] via Lightweight Directory Access Protocol (LDAP). The actors would additionally delete event logs through the wevtutil utility [T1070.001].
After gaining initial access to the network, the actors pursued further access to accounts with access to sensitive information on shipments, such as train schedules and shipping manifests. These accounts contained information on aid shipments to Ukraine, including:
sender,
recipient,
train/plane/ship numbers,
point of departure,
destination,
container registration numbers,
travel route, and
cargo contents.
In at least one instance, the actors attempted to use voice phishing [T1566.004] to gain access to privileged accounts by impersonating IT staff.
Malware
Unit 26165’s use of malware in this campaign ranged from gaining initial access to establishing persistence and exfiltrating data. In some cases, the attack chain resulted in multiple pieces of malware being deployed in succession. The actors used dynamic link library (DLL) search order hijacking [T1574.001] to facilitate malware execution. There were a number of known malware variants tied to this campaign against logistics sector victims, including:
While other malware variants, such as OCEANMAP and STEELHOOK, [8] were not directly observed targeting logistics or IT entities, their deployment against victims in other sectors in Ukraine and other Western countries suggest that they could be deployed against logistics and IT entities should the need arise.
Persistence
In addition to the abovementioned mailbox permissions abuse, unit 26165 actors also used scheduled tasks [T1053.005], run keys [T1547.001], and placed malicious shortcuts [T1547.009] in the startup folder to establish persistence.
Exfiltration
GRU unit 26165 actors used a variety of methods for data exfiltration that varied based on the victim environment, including both malware and living off the land binaries. PowerShell commands [T1059.001] were often used to prepare data for exfiltration; for example, the actors prepared zip archives [T1560.001] for upload to their own infrastructure.
The actors also used server data exchange protocols and Application Programming Interfaces (APIs) such as Exchange Web Services (EWS) and Internet Message Access Protocol (IMAP) [T1114.002] to exfiltrate data from email servers. In multiple instances, the actors used periodic EWS queries [T1119] to collect new emails sent and received since the last data exfiltration [T1029]. The actors typically used infrastructure in close geographic proximity to the victim. Long gaps between exfiltration, the use of trusted and legitimate protocols, and the use of local infrastructure allowed for long-term collection of sensitive data to go undetected.
Connections to Targeting of IP Cameras
In addition to targeting logistics entities, unit 26165 actors likely used access to private cameras at key locations, such as near border crossings, military installations, and rail stations, to track the movement of materials into Ukraine. The actors also used legitimate municipal services, such as traffic cams.
The actors targeted Real Time Streaming Protocol (RTSP) servers hosting IP cameras primarily located in Ukraine as early as March 2022 in a large-scale campaign, which included attempts to enumerate devices [T1592] and gain access to the cameras’ feeds [T1125]. Actor-controlled servers sent RTSP DESCRIBE requests destined for RTSP servers, primarily hosting IP cameras [T1090.002]. The DESCRIBE requests were crafted to obtain access to IP cameras located on logically distinct networks from that of the routers that received the request. The requests included Base64-encoded credentials for the RTSP server, which included publicly documented default credentials and likely generic attempts to brute force access to the devices [T1110]. An example of an RTSP request is shown in Figure 3.
Successful RTSP 200 OK responses contained a snapshot of the IP camera’s image and IP camera metadata such as video codec, resolution, and other properties depending on the IP camera’s configuration.
From a sample available to the authoring agencies of over 10,000 cameras targeted via this effort, the geographic distribution of victims showed a strong focus on cameras in Ukraine and border countries, as shown in Table 1:
Table 1: Geographic distribution of targeted IP cameras
Country
Percentage of Total Attempts
Ukraine
81.0%
Romania
9.9%
Poland
4.0%
Hungary
2.8%
Slovakia
1.7%
Others
0.6%
Mitigation Actions
General Security Mitigations
Architecture and Configuration
Employ appropriate network segmentation [D3-NI] and restrictions to limit access and utilize additional attributes (such as device information, environment, and access path) when making access decisions [D3-AMED].
Consider Zero Trust principles when designing systems. Base product choices on how those products can solve specific risks identified as part of the end-to-end design. [9]
Ensure that host firewalls and network security appliances (e.g., firewalls) are configured to only allow legitimately needed data flows between devices and servers to prevent lateral movement [D3-ITF]. Alert on attempts to connect laterally between host devices or other unusual data flows.
Use automated tools to audit access logs for security concerns and identify anomalous access requests [D3-RAPA].
For organizations using on-premises authentication and email services, block and alert on NTLM/SMB requests to external infrastructure [D3-OTF].
Utilize endpoint, detection, and response (EDR) and other cybersecurity solutions on all systems, prioritizing high value systems with large amounts of sensitive data such as mail servers and domain controllers [D3-PM] first.
Perform threat and attack modeling to understand how sensitive systems may be compromised within an organization’s specific architecture and security controls. Use this to develop a monitoring strategy to detect compromise attempts and select appropriate products to enact this strategy.
Collect and monitor Windows logs for certain events, especially for events that indicate that a log was cleared unexpectedly [D3-SFA].
Enable optional security features in Windows to harden endpoints and mitigate initial access techniques [D3-AH]:
Enable attack surface reduction rules to prevent executable content from email [D3-ABPI].
Enable attack surface reduction rules to prevent execution of files from globally writeable directories, such as Downloads or %APPDATA% [D3-EAL].
Unless users are involved in the development of scripts, limit the local execution of scripts (such as batch scripts, VBScript, JScript/JavaScript, and PowerShell [10]) to known scripts [D3-EI], and audit execution attempts.
Disable Windows Host Scripting functionality and configure PowerShell to run in Constrained mode [D3-ACH].
Where feasible, implement allowlisting for applications and scripts to limit execution to only those needed for authorized activities, blocking all others by default [D3-EAL].
Consider using open source SIGMA rules as a baseline for detecting and alerting on suspicious file execution or command parameters [D3-PSA].
Use services that provide enhanced browsing services and safe link checking [D3-URA]. Significant reductions in successful spearphishing attempts were noted when email providers began offering link checking and automatic file detonation to block malicious content.
Where possible, block logins from public VPNs, including exit nodes in the same country as target systems, or, if they need to be allowed, alert on them for further investigation. Most organizations should not need to allow incoming traffic, especially logins to systems, from VPN services [D3-NAM].
Educate users to only use approved corporate systems for relevant government and military business and avoid the use of personal accounts on cloud email providers to conduct official business. Network administrators should also audit both email and web request logs to detect such activity.
Many organizations may not need to allow outgoing traffic to hosting and API mocking services, which are frequently used by GRU unit 26165. Organizations should consider alerting on or blocking the following services, with exceptions allowlisted for legitimate activity [D3-DNSDL].
*.000[.]pe
*.1cooldns[.]com
*.42web[.]io
*.4cloud[.]click
*.accesscan[.]org
*.bumbleshrimp[.]com
*.camdvr[.]org
*.casacam[.]net
*.ddnsfree[.]com
*.ddnsgeek[.]com
*.ddnsguru[.]com
*.dynuddns[.]com
*.dynuddns[.]net
*.free[.]nf
*.freeddns[.]org
*.frge[.]io
*.glize[.]com
*.great-site[.]net
*.infinityfreeapp[.]com
*.kesug[.]com
*.loseyourip[.]com
*.lovestoblog[.]com
*.mockbin[.]io
*.mockbin[.]org
*.mocky[.]io
*.mybiolink[.]io
*.mysynology[.]net
*.mywire[.]org
*.ngrok[.]io
*.ooguy[.]com
*.pipedream[.]net
*.rf[.]gd
*.urlbae[.]com
*.webhook[.]site
*.webhookapp[.]com
*.webredirect[.]org
*.wuaze[.]com
Heuristic detections for web requests to new subdomains, including of the above providers, may uncover malicious phishing activity [D3-DNRA]. Logging the requests for each sub-domain requested by users on a network, such as in DNS or firewall logs, may enable system administrators to identify new targeting and victims.
Identity and Access Management
Organizations should take measures to ensure strong access controls and mitigate against common credential theft techniques:
Use MFA with strong factors, such as passkeys or PKI smartcards, and require regular re-authentication [D3-MFA]. [11], [12] Strong authentication factors are not guessable using dictionary techniques, so they resist brute force attempts.
Implement other mitigations for privileged accounts: including limiting the number of admin accounts, considering using hardware MFA tokens, and regularly reviewing all privileged user accounts [D3-JFAPA].
Separate privileged accounts by role and alert on misuse of privileged accounts [D3-UAP]. For example, email administrator accounts should be different from domain administrator accounts.
Reduce reliance on passwords; instead, consider using services like single sign-on [D3-TBA].
For organizations using on-premises authentication and email services, plan to disable NTLM entirely and migrate to more robust authentication processes such as PKI certificate authentication.
Do not store passwords in Group Policy Preferences (GPP). Remove all passwords previously included in GPP and change all passwords on the corresponding accounts [D3-CH]. [13]
Use account throttling or account lockout [D3-ANET]:
Throttling is preferred to lockout. Throttling progressively increases time delay between successive login attempts.
Account lockout can leave legitimate users unable to access their accounts and requires access to an account recovery process.
Account lockout can provide a malicious actor with an easy way to launch a Denial of Service (DoS).
If using lockout, then allowing 5 to 10 attempts before lockout is recommended.
Use a service to check for compromised passwords before using them [D3-SPP]. For example, “Have I Been Pwned” can be used to check whether a password has been previously compromised without disclosing the potential password.
Change all default credentials [D3-CRO] and disable protocols that use weak authentication (e.g., clear-text passwords or outdated and vulnerable authentication or encryption protocols) or do not support multi-factor authentication [D3-ACH] [D3-ET]. Always configure access controls carefully to ensure that only well-maintained and well-authenticated accounts have access. [13]
IP Camera Mitigations
The following mitigation techniques for IP cameras can be used to defend against this type of malicious activity:
Ensure IP cameras are currently supported. Replace devices that are out of support.
Apply security patches and firmware updates to all IP cameras [D3-SU].
Disable remote access to the IP camera, if unnecessary [D3-ITF].
Ensure cameras are protected by a security appliance, if possible, such as by using a firewall to prevent communication with the camera from IP addresses not on an allowlist [D3-NAM].
If remote access to IP camera feeds is required, ensure authentication is enabled [D3-AA] and use a VPN to connect remotely [D3-ET]. Use MFA for management accounts if supported [D3-MFA].
Disable Universal Plug and Play (UPnP), Peer-to-Peer (P2P), and Anonymous Visit features on IP cameras and routers [D3-NI].
Turn off other ports/services not in use (e.g., FTP, web interface, etc.) [D3-ACH].
If supported, enable authenticated RTSP access only [D3-AA].
Review all authentication activity for remote access to make sure it is valid and expected [D3-UBA]. Investigate any unexpected or unusual activity.
Audit IP camera user accounts to ensure they are an accurate reflection of your organization and that they are being used as expected [D3-UAP].
Configure, tune, and monitor logging—if available—on the IP camera.
Indicators of Compromise (IOCs)
Note: Specific IoCs may no longer be actor controlled, may themselves be compromised infrastructure or email accounts, or may be shared infrastructure such as public VPN or Tor exit nodes. Care should be taken when basing triaging logs or developing detection rules on these indicators. GRU unit 26165 almost certainly uses extensive further infrastructure and TTPs not specifically listed in this report.
Utilities and scripts
Legitimate utilities
Unauthorized or unusual use of the following legitimate utilities can be an indication of a potential compromise:
ntdsutil – A legitimate Windows executable used by threat actors to export contents of Active Directory
wevtutil – A legitimate Windows executable used by threat actors to delete event logs
vssadmin – A legitimate Windows executable possibly used by threat actors to make a copy of the server’s C: drive
ADexplorer – A legitimate window executable to view, edit, and backup Active Directory Certificate Services
OpenSSH – The Windows version of a legitimate open source SSH client
schtasks – A legitimate Windows executable used to create persistence using scheduled tasks
whoami – A legitimate Windows executable used to retrieve the name of the current user
tasklist – A legitimate Windows executable used to retrieve the list of running processes
hostname – A legitimate Windows executable used to retrieve the device name
arp – A legitimate Windows executable used to retrieve the ARP table for mapping the network environment
systeminfo – A legitimate Windows executable used to retrieve a comprehensive summary of device and operating system information
net – A legitimate Windows executable used to retrieve detailed user information
wmic – A legitimate Windows executable used to interact with Windows Management Instrumentation (WMI), such as to retrieve letters assigned to logical partitions on storage drives
cacls – A legitimate Windows executable used to modify permissions on files
icacls – A legitimate Windows executable used to modify permissions to files and handle integrity levels and ownership
ssh – A legitimate Windows executable used to establish network shell connections
reg – A legitimate Windows executable used to add to or modify the system registry
Note: Additional heuristics are needed for effective hunting for these and other living off the land (LOTL) binaries to avoid being overwhelmed by false positives if these legitimate management tools are used regularly. See the joint guide, Identifying and Mitigating Living Off the Land Techniques, for guidance on developing a multifaceted cybersecurity strategy that enables behavior analytics, anomaly detection, and proactive hunting, which are part of a comprehensive approach to mitigating cyber threats that employ LOTL techniques.
Malicious scripts
Certipy – An open source python tool for enumerating and abusing Active Directory Certificate Services
Get-GPPPassword.py – An open source python script for finding insecure passwords stored in Group Policy Preferences
ldap-dump.py – A script for enumerating user accounts and other information in Active Directory
Hikvision backdoor string: “YWRtaW46MTEK”
Suspicious command lines
While the following utilities are legitimate, and using them with the command lines shown may also be legitimate, these command lines are often used during malicious activities and could be an indication of a compromise:
edge.exe “-headless-new -disable-gpu”
ntdsutil.exe “activate instance ntds” ifm “create full C:temp[a-z]{3}” quit quit
Disclaimer: These IP addresses date June 2024 through August 2024. The authoring agencies recommend organizations investigate or vet these IP addresses prior to taking action, such as blocking.
June 2024
July 2024
August 2024
192[.]162[.]174[.]94
207[.]244[.]71[.]84
31[.]135[.]199[.]145
79[.]184[.]25[.]198
91[.]149[.]253[.]204
103[.]97[.]203[.]29
162[.]210[.]194[.]2
31[.]42[.]4[.]138
79[.]185[.]5[.]142
91[.]149[.]254[.]75
209[.]14[.]71[.]127
46[.]112[.]70[.]252
83[.]10[.]46[.]174
91[.]149[.]255[.]122
109[.]95[.]151[.]207
46[.]248[.]185[.]236
83[.]168[.]66[.]145
91[.]149[.]255[.]19
64[.]176[.]67[.]117
83[.]168[.]78[.]27
91[.]149[.]255[.]195
64[.]176[.]69[.]196
83[.]168[.]78[.]31
91[.]221[.]88[.]76
64[.]176[.]70[.]18
83[.]168[.]78[.]55
93[.]105[.]185[.]139
64[.]176[.]70[.]238
83[.]23[.]130[.]49
95[.]215[.]76[.]209
64[.]176[.]71[.]201
83[.]29[.]138[.]115
138[.]199[.]59[.]43
70[.]34[.]242[.]220
89[.]64[.]70[.]69
147[.]135[.]209[.]245
70[.]34[.]243[.]226
90[.]156[.]4[.]204
178[.]235[.]191[.]182
70[.]34[.]244[.]100
91[.]149[.]202[.]215
178[.]37[.]97[.]243
70[.]34[.]245[.]215
91[.]149[.]203[.]73
185[.]234[.]235[.]69
70[.]34[.]252[.]168
91[.]149[.]219[.]158
192[.]162[.]174[.]67
70[.]34[.]252[.]186
91[.]149[.]219[.]23
194[.]187[.]180[.]20
70[.]34[.]252[.]222
91[.]149[.]223[.]130
212[.]127[.]78[.]170
70[.]34[.]253[.]13
91[.]149[.]253[.]118
213[.]134[.]184[.]167
70[.]34[.]253[.]247
91[.]149[.]253[.]198
70[.]34[.]254[.]245
91[.]149[.]253[.]20
Detections
Customized NTLM listener
rule APT28_NTLM_LISTENER {
meta:
description = "Detects NTLM listeners including APT28's custom one"
The cybersecurity industry provides overlapping cyber threat intelligence, IOCs, and mitigation recommendations related to GRU unit 26165 cyber actors. While not all encompassing, the following are the most notable threat group names related under MITRE ATT&CK G0007 and commonly used within the cybersecurity community:
Note: Cybersecurity companies have different methods of tracking and attributing cyber actors, and this may not be a 1:1 correlation to the U.S. government’s understanding for all activity related to these groupings.
Further Reference
To search for the presence of malicious email messages targeting CVE-2023-23397, network defenders may consider using the script published by Microsoft: https://aka.ms/CVE-2023-23397ScriptDoc.
The information and opinions contained in this document are provided “as is” and without any warranties or guarantees. Reference herein to any specific commercial products, process, or service by trade name, trademark, manufacturer, or otherwise, does not constitute or imply its endorsement, recommendation, or favoring by the United States Government, and this guidance shall not be used for advertising or product endorsement purposes.
Purpose
This document was developed in furtherance of the authoring agencies’ cybersecurity missions, including their responsibilities to identify and disseminate threats and to develop and issue cybersecurity specifications and mitigations. This information may be shared broadly to reach all appropriate stakeholders.
Cybersecurity and Infrastructure Security Agency (CISA) and Federal Bureau of Investigation (FBI)
U.S. organizations are encouraged to reporting suspicious or criminal activity related to information in this advisory to CISA via the agency’s Incident Reporting System, its 24/7 Operations Center (report@cisa.gov or 888-282-0870), or your local FBI field office. When available, please include the following information regarding the incident: date, time, and location of the incident; type of activity; number of people affected; type of equipment user for the activity; the name of the submitting company or organization; and a designated point of contact.
Department of Defense Cyber Crime Center (DC3)
Defense Industrial Base Inquiries and Cybersecurity Services: DC3.DCISE@us.af.mil
Estonian National Cyber Security Centre (NCSC-EE): ria@ria.ee
French organizations
French organizations are encouraged to report suspicious activity or incident related to information found in this advisory by contacting ANSSI/CERT-FR by email at cert-fr@ssi.gouv.fr or by phone at: 3218 or +33 9 70 83 32 18.
Conducted follow-on targeting of additional entities in the transportation sector that had business ties to the primary target, exploiting trust relationships to attempt to gain additional access.
Sent requests with Base64-encoded credentials for the RTSP server, which included publicly documented default credentials, and likely were generic attempts to brute force access to the devices.
Abused SOHO devices to facilitate covert cyber operations, as well as proxy malicious activity, via devices with geolocation in proximity to the target.
External actors could send specially crafted emails that cause a connection from the victim to an untrusted location of the actor’s control, leaking the Net-NTLMv2 hash of the victim that the actor could then relay to another service to authenticate as the victim.
An XSS issue was discovered in Roundcube Webmail before 1.2.13, 1.3.x before 1.3.16 and 1.4.x before 1.4.10, where a plaintext email message with JavaScript in a link reference element is mishandled by linkref_addindex in rcube_string_replacer.php.
Roundcube Webmail before 1.4.4 allows arbitrary code execution via shell metacharacters in a configuration setting for im_convert_path or im_identify_path in rcube_image.php.
Employ appropriate network segmentation. Disable Universal Plug and Play (UPnP), Peer-to-Peer (P2P), and Anonymous Visit features on IP cameras and routers.
Limit access and utilize additional attributes (such as device information, environment, and access path) when making access decisions. Configure access controls carefully to ensure that only well-maintained and well-authenticated accounts have access.
Implement host firewall rules to block connections from other devices on the network, other than from authorized management devices and servers, to prevent lateral movement.
Disable Windows Host Scripting functionality and configure PowerShell to run in Constrained mode. Disable protocols that use weak authentication (e.g., clear-text passwords, or outdated and vulnerable authentication or encryption protocols) or do not support multi-factor authentication. Turn off other ports/services not in use (e.g., FTP, web interface, etc.).
Do not allow incoming traffic, especially logins to systems, from public VPN services. Where possible, logins from public VPNs, including exit nodes in the same country as target systems, should be blocked or, if allowed, alerted on for further investigation. Ensure cameras and other Internet of Things devices are protected by a security appliance, if possible.
Heuristic detections for web requests to new subdomains may uncover malicious phishing activity. Logging the requests for each sub-domain requested by users on a network, such as in DNS or firewall logs, may enable system administrators to identify new targeting and victims.
Implement other mitigations for privileged accounts: including limiting the number of admin accounts, considering using hardware MFA tokens, and regularly reviewing all privileged user accounts.
Separate privileged accounts by role and alert on misuse of privileged accounts. Audit user accounts on all devices to ensure they are an accurate reflection of your organization and that they are being used as expected.
Do not store passwords in Group Policy Preferences (GPP). Remove all passwords previously included in GPP and change all passwords on the corresponding accounts.
Use account throttling or account lockout. Throttling progressively increases time delay between successive login attempts. If using account lockout, allow between 5 to 10 attempts before lockout.
Disable protocols that use weak authentication (e.g., clear-text passwords, or outdated and vulnerable authentication or encryption protocols). Use a VPN for remote connections to devices.
KrebsOnSecurity last week was hit by a near record distributed denial-of-service (DDoS) attack that clocked in at more than 6.3 terabits of data per second (a terabit is one trillion bits of data). The brief attack appears to have been a test run for a massive new Internet of Things (IoT) botnet capable of launching crippling digital assaults that few web destinations can withstand. Read on for more about the botnet, the attack, and the apparent creator of this global menace.
KrebsOnSecurity last week was hit by a near record distributed denial-of-service (DDoS) attack that clocked in at more than 6.3 terabits of data per second (a terabit is one trillion bits of data). The brief attack appears to have been a test run for a massive new Internet of Things (IoT) botnet capable of launching crippling digital assaults that few web destinations can withstand. Read on for more about the botnet, the attack, and the apparent creator of this global menace.
For reference, the 6.3 Tbps attack last week was ten times the size of the assault launched against this site in 2016 by the Mirai IoT botnet, which held KrebsOnSecurity offline for nearly four days. The 2016 assault was so large that Akamai – which was providing pro-bono DDoS protection for KrebsOnSecurity at the time — asked me to leave their service because the attack was causing problems for their paying customers.
Since the Mirai attack, KrebsOnSecurity.com has been behind the protection of Project Shield, a free DDoS defense service that Google subsidiary Jigsaw provides to websites offering news, human rights, and election-related content. Google Security Engineer Damian Menscher told KrebsOnSecurity the May 12 attack was the largest Google has ever handled. In terms of sheer size, it is second only to a very similar attack that Cloudflare mitigated and wrote about in April.
After comparing notes with Cloudflare, Menscher said the botnet that launched both attacks bear the fingerprints of Aisuru, a digital siege machine that first surfaced less than a year ago. Menscher said the attack on KrebsOnSecurity lasted less than a minute, hurling large UDP data packets at random ports at a rate of approximately 585 million data packets per second.
“It was the type of attack normally designed to overwhelm network links,” Menscher said, referring to the throughput connections between and among various Internet service providers (ISPs). “For most companies, this size of attack would kill them.”
A graph depicting the 6.5 Tbps attack mitigated by Cloudflare in April 2025. Image: Cloudflare.
The Aisuru botnet comprises a globally-dispersed collection of hacked IoT devices, including routers, digital video recorders and other systems that are commandeered via default passwords or software vulnerabilities. As documented by researchers at QiAnXin XLab, the botnet was first identified in an August 2024 attack on a large gaming platform.
Aisuru reportedly went quiet after that exposure, only to reappear in November with even more firepower and software exploits. In a January 2025 report, XLab found the new and improved Aisuru (a.k.a. “Airashi“) had incorporated a previously unknown zero-day vulnerability in Cambium Networks cnPilot routers.
NOT FORKING AROUND
The people behind the Aisuru botnet have been peddling access to their DDoS machine in public Telegram chat channels that are closely monitored by multiple security firms. In August 2024, the botnet was rented out in subscription tiers ranging from $150 per day to $600 per week, offering attacks of up to two terabits per second.
“You may not attack any measurement walls, healthcare facilities, schools or government sites,” read a notice posted on Telegram by the Aisuru botnet owners in August 2024.
Interested parties were told to contact the Telegram handle “@yfork” to purchase a subscription. The account @yfork previously used the nickname “Forky,” an identity that has been posting to public DDoS-focused Telegram channels since 2021.
According to the FBI, Forky’s DDoS-for-hire domains have been seized in multiple law enforcement operations over the years. Last year, Forky said on Telegram he was selling the domain stresser[.]best, which saw its servers seized by the FBI in 2022 as part of an ongoing international law enforcement effort aimed at diminishing the supply of and demand for DDoS-for-hire services.
“The operator of this service, who calls himself ‘Forky,’ operates a Telegram channel to advertise features and communicate with current and prospective DDoS customers,” reads an FBI seizure warrant (PDF) issued for stresser[.]best. The FBI warrant stated that on the same day the seizures were announced, Forky posted a link to a story on this blog that detailed the domain seizure operation, adding the comment, “We are buying our new domains right now.”
A screenshot from the FBI’s seizure warrant for Forky’s DDoS-for-hire domains shows Forky announcing the resurrection of their service at new domains.
Approximately ten hours later, Forky posted again, including a screenshot of the stresser[.]best user dashboard, instructing customers to use their saved passwords for the old website on the new one.
A review of Forky’s posts to public Telegram channels — as indexed by the cyber intelligence firms Unit 221B and Flashpoint — reveals a 21-year-old individual who claims to reside in Brazil [full disclosure: Flashpoint is currently an advertiser on this blog].
Since late 2022, Forky’s posts have frequently promoted a DDoS mitigation company and ISP that he operates called botshield[.]io. The Botshield website is connected to a business entity registered in the United Kingdom called Botshield LTD, which lists a 21-year-old woman from Sao Paulo, Brazil as the director. Internet routing records indicate Botshield (AS213613) currently controls several hundred Internet addresses that were allocated to the company earlier this year.
Domaintools.com reports that botshield[.]io was registered in July 2022 to a Kaike Southier Leite in Sao Paulo. A LinkedIn profile by the same name says this individual is a network specialist from Brazil who works in “the planning and implementation of robust network infrastructures, with a focus on security, DDoS mitigation, colocation and cloud server services.”
MEET FORKY
Image: Jaclyn Vernace / Shutterstock.com.
In his posts to public Telegram chat channels, Forky has hardly attempted to conceal his whereabouts or identity. In countless chat conversations indexed by Unit 221B, Forky could be seen talking about everyday life in Brazil, often remarking on the extremely low or high prices in Brazil for a range of goods, from computer and networking gear to narcotics and food.
Reached via Telegram, Forky claimed he was “not involved in this type of illegal actions for years now,” and that the project had been taken over by other unspecified developers. Forky initially told KrebsOnSecurity he had been out of the botnet scene for years, only to concede this wasn’t true when presented with public posts on Telegram from late last year that clearly showed otherwise.
Forky denied being involved in the attack on KrebsOnSecurity, but acknowledged that he helped to develop and market the Aisuru botnet. Forky claims he is now merely a staff member for the Aisuru botnet team, and that he stopped running the botnet roughly two months ago after starting a family. Forky also said the woman named as director of Botshield is related to him.
Forky offered equivocal, evasive responses to a number of questions about the Aisuru botnet and his business endeavors. But on one point he was crystal clear:
“I have zero fear about you, the FBI, or Interpol,” Forky said, asserting that he is now almost entirely focused on their hosting business — Botshield.
Forky declined to discuss the makeup of his ISP’s clientele, or to clarify whether Botshield was more of a hosting provider or a DDoS mitigation firm. However, Forky has posted on Telegram about Botshield successfully mitigating large DDoS attacks launched against other DDoS-for-hire services.
DomainTools finds the same Sao Paulo street address in the registration records for botshield[.]io was used to register several other domains, including cant-mitigate[.]us. The email address in the WHOIS records for that domain is forkcontato@gmail.com, which DomainTools says was used to register the domain for the now-defunct DDoS-for-hire service stresser[.]us, one of the domains seized in the FBI’s 2023 crackdown.
On May 8, 2023, the U.S. Department of Justiceannounced the seizure of stresser[.]us, along with a dozen other domains offering DDoS services. The DOJ said ten of the 13 domains were reincarnations of services that were seized during a prior sweep in December, which targeted 48 top stresser services (also known as “booters”).
Forky claimed he could find out who attacked my site with Aisuru. But when pressed a day later on the question, Forky said he’d come up empty-handed.
“I tried to ask around, all the big guys are not retarded enough to attack you,” Forky explained in an interview on Telegram. “I didn’t have anything to do with it. But you are welcome to write the story and try to put the blame on me.”
THE GHOST OF MIRAI
The 6.3 Tbps attack last week caused no visible disruption to this site, in part because it was so brief — lasting approximately 45 seconds. DDoS attacks of such magnitude and brevity typically are produced when botnet operators wish to test or demonstrate their firepower for the benefit of potential buyers. Indeed, Google’s Menscher said it is likely that both the May 12 attack and the slightly larger 6.5 Tbps attack against Cloudflare last month were simply tests of the same botnet’s capabilities.
In many ways, the threat posed by the Aisuru/Airashi botnet is reminiscent of Mirai, an innovative IoT malware strain that emerged in the summer of 2016 and successfully out-competed virtually all other IoT malware strains in existence at the time.
As first revealed by KrebsOnSecurity in January 2017, the Mirai authors were two U.S. men who co-ran a DDoS mitigation service — even as they were selling far more lucrative DDoS-for-hire services using the most powerful botnet on the planet.
Less than a week after the Mirai botnet was used in a days-long DDoS against KrebsOnSecurity, the Mirai authors published the source code to their botnet so that they would not be the only ones in possession of it in the event of their arrest by federal investigators.
Ironically, the leaking of the Mirai source is precisely what led to the eventual unmasking and arrest of the Mirai authors, who went on to serve probation sentences that required them to consult with FBI investigators on DDoS investigations. But that leak also rapidly led to the creation of dozens of Mirai botnet clones, many of which were harnessed to fuel their own powerful DDoS-for-hire services.
Menscher told KrebsOnSecurity that as counterintuitive as it may sound, the Internet as a whole would probably be better off if the source code for Aisuru became public knowledge. After all, he said, the people behind Aisuru are in constant competition with other IoT botnet operators who are all striving to commandeer a finite number of vulnerable IoT devices globally.
Such a development would almost certainly cause a proliferation of Aisuru botnet clones, he said, but at least then the overall firepower from each individual botnet would be greatly diminished — or at least within range of the mitigation capabilities of most DDoS protection providers.
Barring a source code leak, Menscher said, it would be nice if someone published the full list of software exploits being used by the Aisuru operators to grow their botnet so quickly.
“Part of the reason Mirai was so dangerous was that it effectively took out competing botnets,” he said. “This attack somehow managed to compromise all these boxes that nobody else knows about. Ideally, we’d want to see that fragmented out, so that no [individual botnet operator] controls too much.”
CVSS v4 8.3
ATTENTION: Low attack complexity
Vendor: Mitsubishi Electric Iconics Digital Solutions, Mitsubishi Electric
Equipment: ICONICS Product Suite and Mitsubishi Electric MC Works64
Vulnerability: Execution with Unnecessary Privileges
2. RISK EVALUATION
Successful exploitation of this vulnerability could result in information tampering on the target workstation.
3. TECHNICAL DETAILS
3.1 AFFECTED PRODUCTS
Mitsubishi Electric Iconics Digital Solutions reports that the following versions of ICONICS Product Suite and Mitsubishi Electric MC Works64 are affected:
GENESIS64 AlarmWorX Multimedia (AlarmWorX64 MMX): All Versions
Mitsubishi Electric MC Works64 AlarmWorX Multimedia (AlarmWorX64 MMX): All versions
3.2 VULNERABILITY OVERVIEW
3.2.1 EXECUTION WITH UNNECESSARY PRIVILEGES CWE-250
An execution with unnecessary privileges vulnerability in the AlarmWorX64 MMX Pager agent can provide the potential for information tampering. An attacker could make an unauthorized write to arbitrary files by creating a symbolic link from a file used as a write destination by the Pager Agent service of GENESIS64 and MC Works64 to a target file. This could allow the attacker to destroy the file on a PC with GENESIS64 or MC Works64 installed, resulting in a denial-of-service (DoS) condition on the PC.
CVE-2025-0921 has been assigned to this vulnerability. A CVSS v3.1 base score of 6.5 has been calculated; the CVSS vector string is (AV:L/AC:L/PR:L/UI:N/S:C/C:N/I:H/A:N).
A CVSS v4 score has also been calculated for CVE-2025-0921. A base score of 8.3 has been calculated; the CVSS vector string is (AV:L/AC:L/AT:N/PR:L/UI:N/VC:N/VI:H/VA:H/SC:N/SI:H/SA:H.
3.3 BACKGROUND
CRITICAL INFRASTRUCTURE SECTORS: Critical Manufacturing
COUNTRIES/AREAS DEPLOYED: Worldwide
COMPANY HEADQUARTERS LOCATION: Japan
3.4 RESEARCHER
Asher Davila and Malav Vyas from Palo Alto Networks reported this vulnerability to Mitsubishi Electric and CISA.
4. MITIGATIONS
Mitsubishi Electric recommends that users take the following mitigations to minimize the risk of exploiting this vulnerability:
If you do not need to use the multi-agent notification feature, please uninstall it. The multi-agent notification feature is not included in the default installation of GENESIS64TM version 10.97.3 or later. For users engaging the multi-agent notification feature who do not also need to the Pager agent, please execute a custom installation of the multi-agent notification feature and skip the installation of the Pager agent.
Please configure the PCs with the affected product installed so that only an administrator can log in.
PCs with the affected product installed should be configured to block remote logins from untrusted networks and hosts, and from non-administrator users.
Block unauthorized access by using a firewall or virtual private network (VPN), etc., and allow remote login only to administrators when connecting the PCs with the affected product installed to the Internet.
Restrict physical access to the PC with the affected product installed and the network to which the PC is connected to prevent unauthorized physical access.
Do not click on web links in emails from untrusted sources. Also, do not open attachments in untrusted emails.
Mitsubishi Electric Iconics Digital Solutions and Mitsubishi Electric recommends updating the ICONICS Suite with the latest security patches as they become available. ICONICS Suite security patches may be found at the following link: https://partners.iconics.com/Home.aspx. Note that a login is required.
Refer to the Mitsubishi Electric Iconics Digital Solutions Whitepaper on Security Vulnerabilities, the most recent version of which can be found at: https://iconics.com/About/Security/CERT
Refer to the Mitsubishi Electric security advisory at: https://www.mitsubishielectric.com/psirt/vulnerability/pdf/2025-002_en.pdf for information on the availability of the security updates.
CISA recommends users take defensive measures to minimize the risk of exploitation of this vulnerability, such as:
Minimize network exposure for all control system devices and/or systems, ensuring they are not accessible from the Internet.
CISA reminds organizations to perform proper impact analysis and risk assessment prior to deploying defensive measures.
CISA also provides a section for control systems security recommended practices on the ICS webpage on cisa.gov/ics. Several CISA products detailing cyber defense best practices are available for reading and download, including Improving Industrial Control Systems Cybersecurity with Defense-in-Depth Strategies.
CISA encourages organizations to implement recommended cybersecurity strategies for proactive defense of ICS assets.
Additional mitigation guidance and recommended practices are publicly available on the ICS webpage at cisa.gov/ics in the technical information paper, ICS-TIP-12-146-01B–Targeted Cyber Intrusion Detection and Mitigation Strategies.
Organizations observing suspected malicious activity should follow established internal procedures and report findings to CISA for tracking and correlation against other incidents.
CISA also recommends users take the following measures to protect themselves from social engineering attacks:
Refer to Recognizing and Avoiding Email Scams for more information on avoiding email scams.
Refer to Avoiding Social Engineering and Phishing Attacks for more information on social engineering attacks.
No known public exploitation specifically targeting this vulnerability has been reported to CISA at this time. This vulnerability is not exploitable remotely.
5. UPDATE HISTORY
Vendor: Mitsubishi Electric Iconics Digital Solutions, Mitsubishi Electric
Equipment: ICONICS Product Suite and Mitsubishi Electric MC Works64
Vulnerability: Execution with Unnecessary Privileges
2. RISK EVALUATION
Successful exploitation of this vulnerability could result in information tampering on the target workstation.
3. TECHNICAL DETAILS
3.1 AFFECTED PRODUCTS
Mitsubishi Electric Iconics Digital Solutions reports that the following versions of ICONICS Product Suite and Mitsubishi Electric MC Works64 are affected:
GENESIS64 AlarmWorX Multimedia (AlarmWorX64 MMX): All Versions
Mitsubishi Electric MC Works64 AlarmWorX Multimedia (AlarmWorX64 MMX): All versions
An execution with unnecessary privileges vulnerability in the AlarmWorX64 MMX Pager agent can provide the potential for information tampering. An attacker could make an unauthorized write to arbitrary files by creating a symbolic link from a file used as a write destination by the Pager Agent service of GENESIS64 and MC Works64 to a target file. This could allow the attacker to destroy the file on a PC with GENESIS64 or MC Works64 installed, resulting in a denial-of-service (DoS) condition on the PC.
Asher Davila and Malav Vyas from Palo Alto Networks reported this vulnerability to Mitsubishi Electric and CISA.
4. MITIGATIONS
Mitsubishi Electric recommends that users take the following mitigations to minimize the risk of exploiting this vulnerability:
If you do not need to use the multi-agent notification feature, please uninstall it. The multi-agent notification feature is not included in the default installation of GENESIS64TM version 10.97.3 or later. For users engaging the multi-agent notification feature who do not also need to the Pager agent, please execute a custom installation of the multi-agent notification feature and skip the installation of the Pager agent.
Please configure the PCs with the affected product installed so that only an administrator can log in.
PCs with the affected product installed should be configured to block remote logins from untrusted networks and hosts, and from non-administrator users.
Block unauthorized access by using a firewall or virtual private network (VPN), etc., and allow remote login only to administrators when connecting the PCs with the affected product installed to the Internet.
Restrict physical access to the PC with the affected product installed and the network to which the PC is connected to prevent unauthorized physical access.
Do not click on web links in emails from untrusted sources. Also, do not open attachments in untrusted emails.
Mitsubishi Electric Iconics Digital Solutions and Mitsubishi Electric recommends updating the ICONICS Suite with the latest security patches as they become available. ICONICS Suite security patches may be found at the following link: https://partners.iconics.com/Home.aspx. Note that a login is required.
Refer to the Mitsubishi Electric Iconics Digital Solutions Whitepaper on Security Vulnerabilities, the most recent version of which can be found at: https://iconics.com/About/Security/CERT
Organizations observing suspected malicious activity should follow established internal procedures and report findings to CISA for tracking and correlation against other incidents.
CISA also recommends users take the following measures to protect themselves from social engineering attacks:
No known public exploitation specifically targeting this vulnerability has been reported to CISA at this time. This vulnerability is not exploitable remotely.